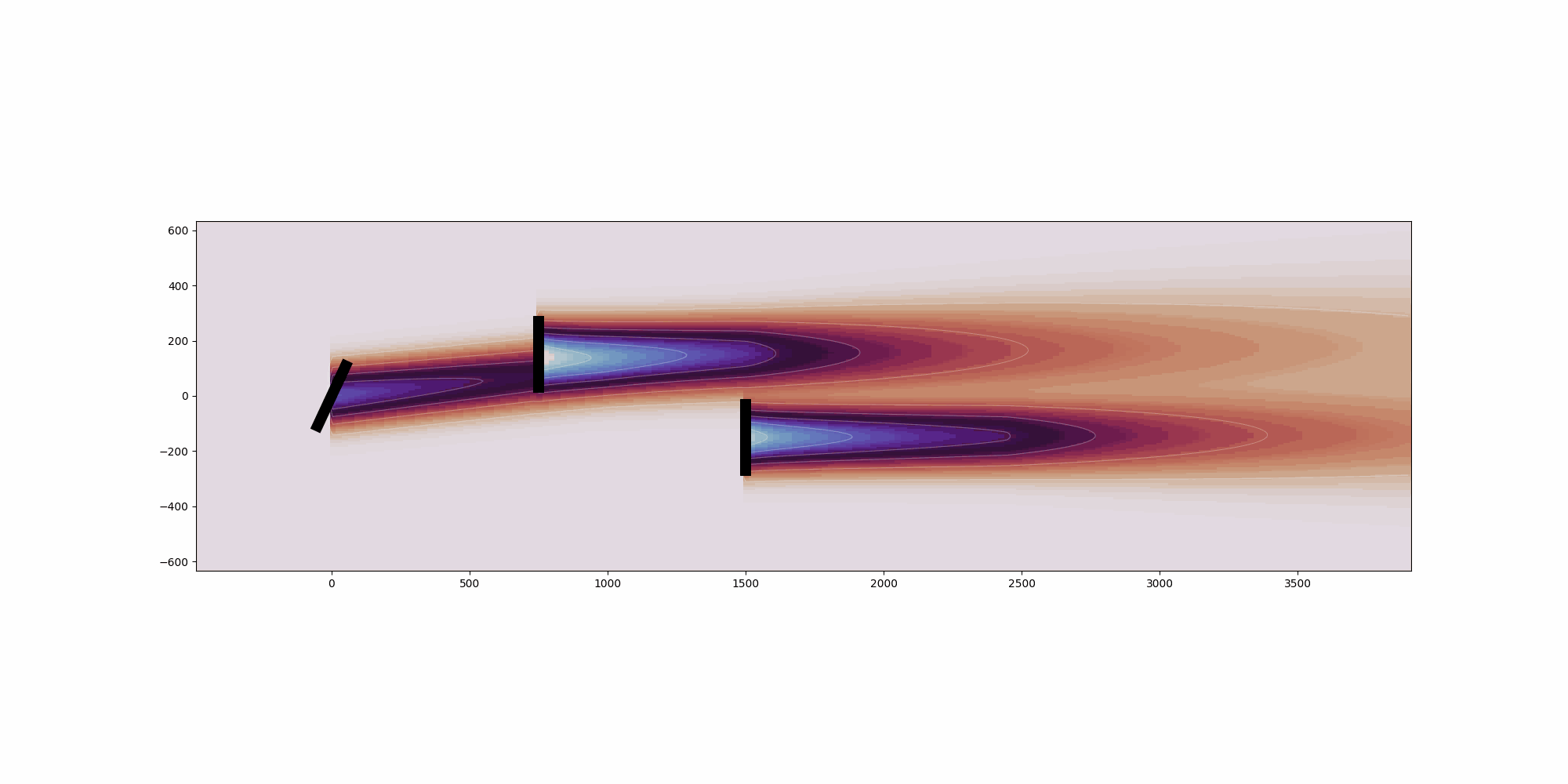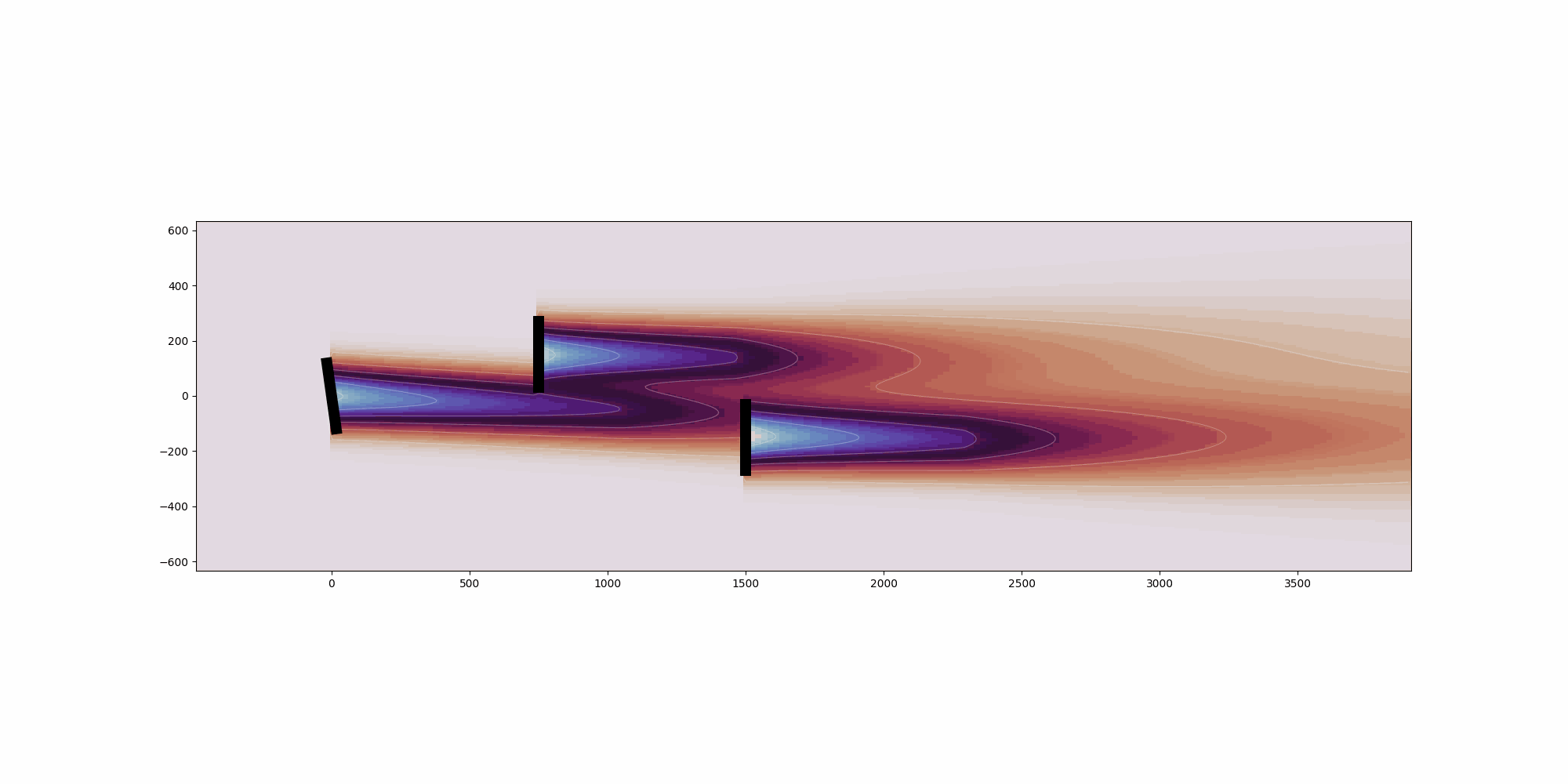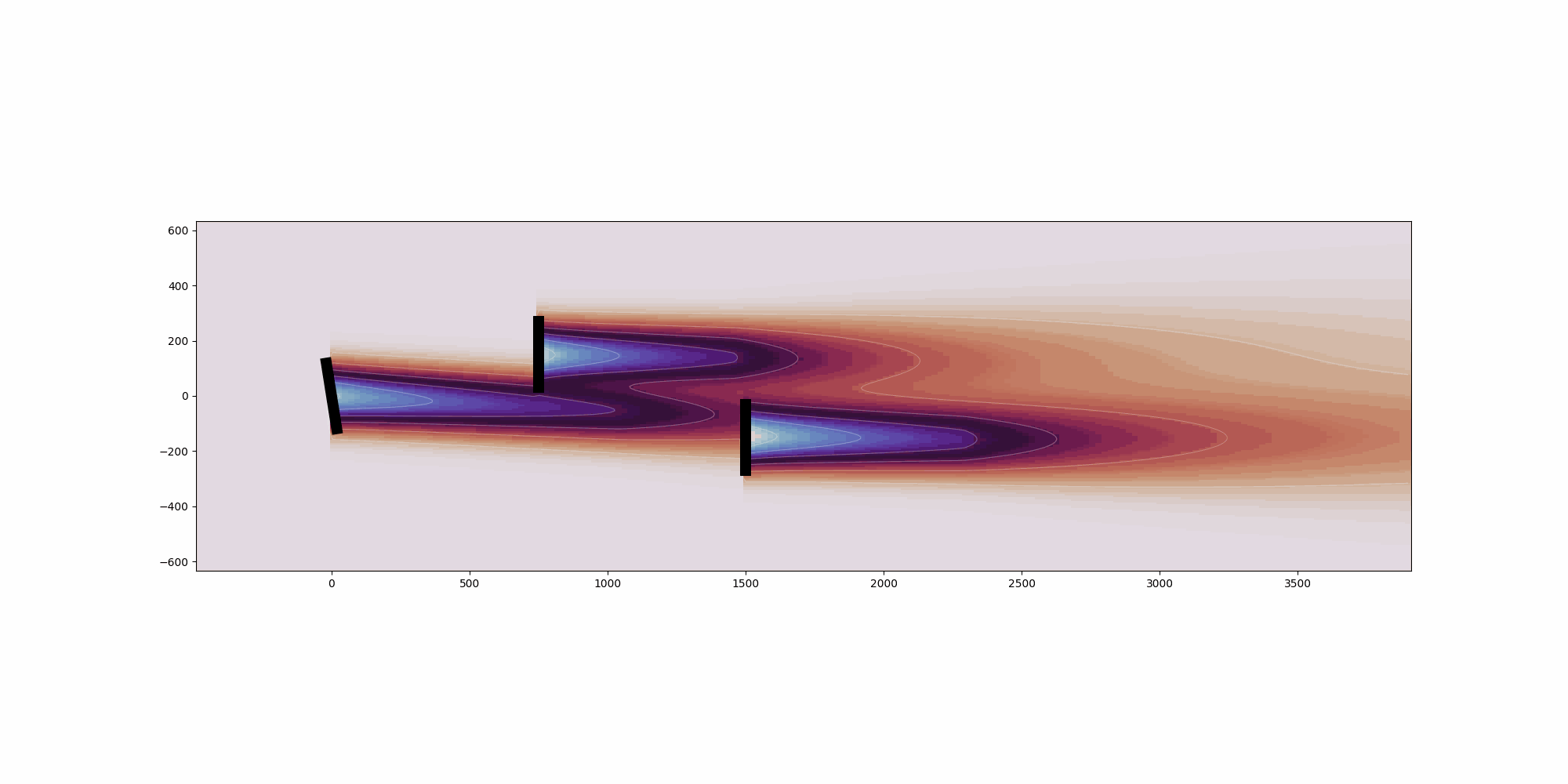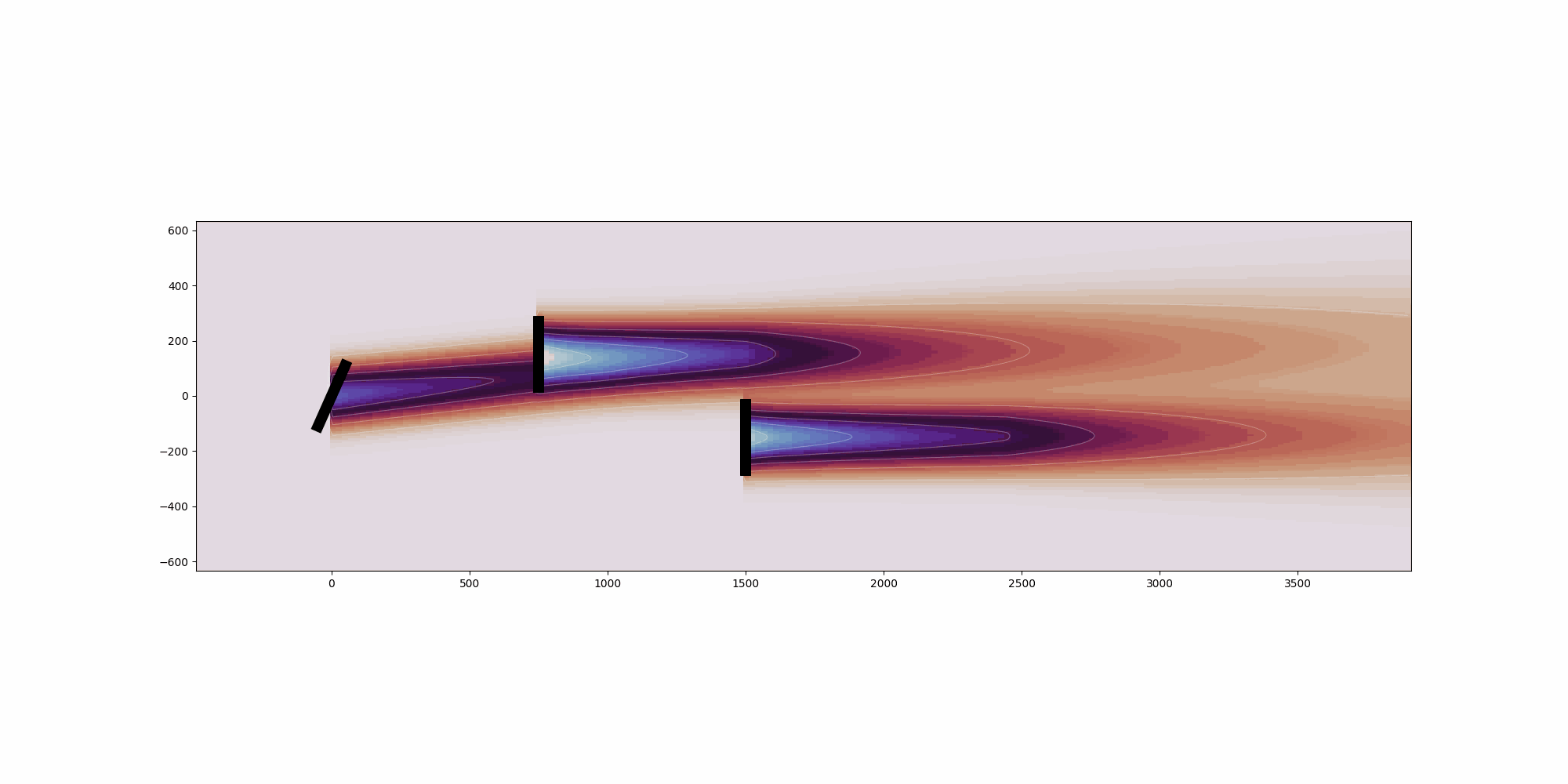
from __future__ import annotations
import copy
import inspect
from pathlib import Path
from typing import (
Any,
Callable,
Iterable,
Tuple,
Union,
)
import attrs
import numpy as np
import numpy.typing as npt
from attrs import Attribute, define
### Define general data types used throughout
floris_float_type = np.float64
NDArrayFloat = npt.NDArray[floris_float_type]
NDArrayInt = npt.NDArray[np.int_]
NDArrayFilter = Union[npt.NDArray[np.int_], npt.NDArray[np.bool_]]
NDArrayObject = npt.NDArray[np.object_]
NDArrayBool = npt.NDArray[np.bool_]
NDArrayStr = npt.NDArray[np.str_]
### Custom callables for attrs objects and functions
[docs]
def floris_array_converter(data: Iterable) -> np.ndarray:
"""
For a given iterable, convert the data to a numpy array and cast to `floris_float_type`.
If the input is a scalar, np.array() creates a 0-dimensional array, and this is not supported
in FLORIS so this function raises an error.
Args:
data (Iterable): The input data to be converted to a Numpy array.
Raises:
TypeError: Raises if the input data is not iterable.
TypeError: Raises if the input data cannot be converted to a Numpy array.
Returns:
np.ndarray: data converted to a Numpy array and cast to `floris_float_type`.
"""
try:
iter(data)
except TypeError as e:
raise TypeError(e.args[0] + f". Data given: {data}")
try:
a = np.array(data, dtype=floris_float_type)
except (TypeError, ValueError) as e:
raise TypeError(e.args[0] + f". Data given: {data}")
return a
[docs]
def floris_numeric_dict_converter(data: dict) -> dict:
"""
For the given dictionary, convert all the values to a numeric type. If a value is a scalar, it
will be converted to a float. If a value is an iterable, it will be converted to a Numpy
array and cast to `floris_float_type`. If a value is not a numeric type, a TypeError will be
raised.
Args:
data (dict): Dictionary of data to be converted to a numeric type.
Returns:
dict: Dictionary with the same keys and all values converted to a numeric type.
"""
converted_dict = copy.deepcopy(data) # deepcopy -> data is a container and passed by reference
for k, v in data.items():
try:
iter(v)
except TypeError:
# Not iterable so try to cast to float
converted_dict[k] = float(v)
else:
# Iterable so convert to Numpy array
converted_dict[k] = floris_array_converter(v)
return converted_dict
# def array_field(**kwargs) -> Callable:
# """
# A wrapper for the :py:func:`attr.field` function that converts the input to a Numpy array,
# adds a comparison function specific to Numpy arrays, and passes through all additional
# keyword arguments.
# """
# return field(
# converter=floris_array_converter,
# eq=cmp_using(eq=np.array_equal),
# **kwargs
# )
def _attr_serializer(inst: type, field: Attribute, value: Any):
if isinstance(value, np.ndarray):
return value.tolist()
return value
def _attr_floris_filter(inst: Attribute, value: Any) -> bool:
if inst.init is False:
return False
if value is None:
return False
if isinstance(value, np.ndarray):
if value.size == 0:
return False
return True
[docs]
def iter_validator(iter_type, item_types: Union[Any, Tuple[Any]]) -> Callable:
"""
Helper function to generate iterable validators that will reduce the amount of
boilerplate code.
Args:
iter_type (iterable): The type of iterable object that should be validated.
item_types (Union[Any, Tuple[Any]]): The type or types of acceptable item types.
Returns:
Callable: The attr.validators.deep_iterable iterable and instance validator.
"""
validator = attrs.validators.deep_iterable(
member_validator=attrs.validators.instance_of(item_types),
iterable_validator=attrs.validators.instance_of(iter_type),
)
return validator
[docs]
def convert_to_path(fn: str | Path) -> Path:
"""
Converts an input string or ``pathlib.Path`` object to a fully resolved ``pathlib.Path``
object. If the input is a string, it is converted to a pathlib.Path object.
The function then checks if the path exists as an absolute path, a relative path from
the script, or a relative path from the system location. If the path does not exist in
any of these locations, a FileExistsError is raised.
Args:
fn (str | Path): The user input file path or file name.
Raises:
FileExistsError: Raised if :py:attr:`fn` is not able to be found as an absolute path, nor as
a relative path.
TypeError: Raised if :py:attr:`fn` is neither a :py:obj:`str`, nor a :py:obj:`pathlib.Path`.
Returns:
Path: A resolved pathlib.Path object.
"""
if isinstance(fn, str):
fn = Path(fn)
# Get the base path from where the analysis script was run to determine the relative
# path from which `fn` might be based. [1] is where a direct call to this function will be
# located (e.g., testing via pytest), and [-1] is where a direct call to the function via an
# analysis script will be located (e.g., running an example).
base_fn_script = Path(inspect.stack()[-1].filename).resolve().parent
base_fn_sys = Path(inspect.stack()[1].filename).resolve().parent
if isinstance(fn, Path):
absolute_fn = fn.resolve()
relative_fn_script = (base_fn_script / fn).resolve()
relative_fn_sys = (base_fn_sys / fn).resolve()
if absolute_fn.exists():
return absolute_fn
if relative_fn_script.exists():
return relative_fn_script
if relative_fn_sys.exists():
return relative_fn_sys
raise FileExistsError(
f"{fn} could not be found as either a\n"
f" - relative file path from a script: {relative_fn_script}\n"
f" - relative file path from a system location: {relative_fn_sys}\n"
f" - or absolute file path: {absolute_fn}"
)
raise TypeError(f"The passed input: {fn} could not be converted to a pathlib.Path object")
[docs]
@define
class FromDictMixin:
"""
A Mixin class to allow for kwargs overloading when a data class doesn't
have a specific parameter defined. This allows passing of larger dictionaries
to a data class without throwing an error.
"""
[docs]
@classmethod
def from_dict(cls, data: dict):
"""Maps a data dictionary to an `attr`-defined class.
TODO: Add an error to ensure that either none or all the parameters are passed in
Args:
data : dict
The data dictionary to be mapped.
Returns:
cls
The `attr`-defined class.
"""
# Make a copy of the input dict to prevent any side effects
data = copy.deepcopy(data)
# Check for any inputs that aren't part of the class definition
class_attr_names = [a.name for a in cls.__attrs_attrs__]
extra_args = [d for d in data if d not in class_attr_names]
if len(extra_args):
raise AttributeError(
f"The initialization for {cls.__name__} was given extraneous inputs: {extra_args}"
)
kwargs = {a.name: data[a.name] for a in cls.__attrs_attrs__ if a.name in data and a.init}
# Map the inputs must be provided: 1) must be initialized, 2) no default value defined
required_inputs = [
a.name
for a in cls.__attrs_attrs__
if a.init and a.default is attrs.NOTHING
]
undefined = sorted(set(required_inputs) - set(kwargs))
if undefined:
raise AttributeError(
f"The class definition for {cls.__name__} "
f"is missing the following inputs: {undefined}"
)
return cls(**kwargs)
[docs]
def as_dict(self) -> dict:
"""Creates a YAML friendly dictionary that can be saved for future reloading.
This dictionary will contain only `Python` types that can later be converted to their
proper formats. See `_attr_floris_filter` for detail on which attributes are
removed from the export.
Returns:
dict: All key, value pairs required for class recreation.
"""
return attrs.asdict(self, filter=_attr_floris_filter, value_serializer=_attr_serializer)
# Avoids constant redefinition of the same attr.ib properties for model attributes
# from functools import partial, update_wrapper
# def is_default(instance, attribute, value):
# if attribute.default != value:
# raise ValueError(f"{attribute.name} should never be set manually.")
# model_attrib = partial(field, on_setattr=attrs.setters.frozen, validator=is_default)
# update_wrapper(model_attrib, field)
# float_attrib = partial(
# attr.ib,
# converter=float,
# on_setattr=(attr.setters.convert, attr.setters.validate), # type: ignore
# kw_only=True,
# )
# update_wrapper(float_attrib, attr.ib)
# bool_attrib = partial(
# attr.ib,
# converter=bool,
# on_setattr=(attr.setters.convert, attr.setters.validate), # type: ignore
# kw_only=True,
# )
# update_wrapper(bool_attrib, attr.ib)
# int_attrib = partial(
# attr.ib,
# converter=int,
# on_setattr=(attr.setters.convert, attr.setters.validate), # type: ignore
# kw_only=True,
# )
# update_wrapper(int_attrib, attr.ib)