Model Prediction#
RouteE models can be loaded from a large library of pre-trained models. Conventional gasoline (CV), hybrid electric (HEV), plug-in hybrid electric (PHEV), and battery electric (BEV) powertrain types are all available.
A note on PHEVs: Plug-in hybrids have two general operating modes 1) "Charge Depleting" or "EV" mode, where the vehicle relies only on energy from the battery to power the motor and 2) "Charge Sustaining" or "Hybrid" mode, where the vehicle operates like a typical parallel hybrid, using a combination of the combustion energy and electric motor for tractive effort and regenerative braking. Since the operating mode depends on battery state-of-charge and driver decisions, pre-trained RouteE-Powertrain models for both operating modes are provided for all PHEVs and it is up to the user to decide which is most appropriate for a particular application.
import nrel.routee.powertrain as pt
pt.list_available_models()
['2016_TOYOTA_Camry_4cyl_2WD',
'2017_CHEVROLET_Bolt',
'2010_Mazda_3_i-Stop',
'2012_Ford_Focus',
'2012_Ford_Fusion',
'2016_AUDI_A3_4cyl_2WD',
'2016_BMW_328d_4cyl_2WD',
'2016_BMW_i3_REx_PHEV_Charge_Depleting',
'2016_BMW_i3_REx_PHEV_Charge_Sustaining',
'2016_CHEVROLET_Malibu_4cyl_2WD',
'2016_CHEVROLET_Spark_EV',
'2016_CHEVROLET_Volt_Charge_Depleting',
'2016_CHEVROLET_Volt_Charge_Sustaining',
'2016_FORD_C-MAX_(PHEV)_Charge_Depleting',
'2016_FORD_C-MAX_(PHEV)_Charge_Sustaining',
'2016_FORD_C-MAX_HEV',
'2016_FORD_Escape_4cyl_2WD',
'2016_FORD_Explorer_4cyl_2WD',
'2016_HYUNDAI_Elantra_4cyl_2WD',
'2016_HYUNDAI_Sonata_PHEV_Charge_Depleting',
'2016_HYUNDAI_Sonata_PHEV_Charge_Sustaining',
'2016_Hyundai_Tucson_Fuel_Cell',
'2016_KIA_Optima_Hybrid',
'2016_Leaf_24_kWh',
'2016_MITSUBISHI_i-MiEV',
'2016_Nissan_Leaf_30_kWh',
'2016_Nissan_Leaf_30_kWh_0F_110F_steady',
'2016_Nissan_Leaf_30_kWh_0F_110F_transient',
'2016_TESLA_Model_S60_2WD',
'2016_TOYOTA_Camry_4cyl_2WD',
'2016_TOYOTA_Corolla_4cyl_2WD',
'2016_TOYOTA_Corolla_4cyl_2WD_Stochastic',
'2016_TOYOTA_Highlander_Hybrid',
'2016_Toyota_Prius_Two_FWD',
'2017_CHEVROLET_Bolt',
'2017_Maruti_Dzire_VDI',
'2017_Prius_Prime_Charge_Depleting',
'2017_Prius_Prime_Charge_Sustaining',
'2017_Toyota_Highlander_3',
'2020_Chevrolet_Bolt_EV_0F_110F_steady',
'2020_Chevrolet_Bolt_EV_0F_110F_transient',
'2020_Chevrolet_Colorado_2WD_Diesel',
'2020_Chevrolet_Colorado_2WD_Diesel_Stochastic',
'2020_VW_Golf_1',
'2020_VW_Golf_2',
'2021_BMW_iX_xDrive40',
'2021_Cupra_Born',
'2021_Fiat_Panda_Mild_Hybrid',
'2021_Honda_N-Box_G',
'2021_Peugot_3008',
'2022_Ford_F-150_Lightning_4WD',
'2022_MINI_Cooper_SE_Hardtop_2_door',
'2022_Renault_Megane_E-Tech',
'2022_Renault_Zoe_ZE50_R135',
'2022_Tesla_Model_3_RWD',
'2022_Tesla_Model_3_RWD_0F_110F_steady',
'2022_Tesla_Model_3_RWD_0F_110F_transient',
'2022_Tesla_Model_Y_RWD',
'2022_Tesla_Model_Y_RWD_Stochastic',
'2022_Toyota_Avanza_E_J_MT',
'2022_Toyota_RAV4_Hybrid_LE',
'2022_Toyota_RAV4_Hybrid_LE_Stochastic',
'2022_Toyota_Yaris_Hybrid_Mid',
'2022_Volvo_XC40_Recharge_twin',
'2023_Mitsubishi_Pajero_Sport',
'2023_Polestar_2_Long_range_Dual_motor',
'2023_Volvo_C40_Recharge',
'2024_BYD_Dolphin_Active',
'2024_Toyota_Vios_1',
'2024_VinFast_VF_e34',
'2024_Volkswagen_Polo_1',
'BYD_ATTO_3',
'Daycab_new_300kW',
'Daycab_new_400kW',
'Daycab_old_300kW',
'Daycab_old_400kW',
'Maruti_Swift_4cyl_2WD',
'Nissan_Navara',
'Renault_Clio_IV_diesel',
'Renault_Megane_1',
'Sleeper_new_300kW',
'Sleeper_new_400kW',
'Sleeper_old_300kW',
'Sleeper_old_400kW',
'Toyota_Corolla_Cross_Hybrid',
'Toyota_Etios_Liva_diesel',
'Toyota_Hilux_Double_Cab_4WD',
'Toyota_Mirai',
'Transit_Bus_Battery_Electric',
'Transit_Bus_Diesel']
camry = pt.load_model("2016_TOYOTA_Camry_4cyl_2WD")
After loading a model, we can inspect it to see what features (and units) the model expects.
RouteE Powertrain models can have multiple estimators under the hood which have been trained on different feature sets.
For example, there might be an estimator that takes just speed as a link feature and another that takes in speed and grade.
This can be useful if you have sparse data for one feature (like grade) but still want to predict energy consumption.
camry
| Model Summary | |
|---|---|
| Vehicle description | 2016_TOYOTA_Camry_4cyl_2WD trained July 2024 |
| Powertrain type | ICE |
| Number of estimators | 3 |
| Estimator Summary | |
| Feature | speed_mph (mph) |
| Distance | distance (miles) |
| Target | gge (gallons gasoline) |
| Predicted Consumption | 30.279 (miles/gallons gasoline) |
| Real World Predicted Consumption | 25.969 (miles/gallons gasoline) |
| Predict Method | RATE |
| Estimator Summary | |
| Feature | speed_mph (mph) |
| Feature | grade_percent (percent) |
| Distance | distance (miles) |
| Target | gge (gallons gasoline) |
| Predicted Consumption | 30.289 (miles/gallons gasoline) |
| Real World Predicted Consumption | 25.977 (miles/gallons gasoline) |
| Predict Method | RATE |
| Estimator Summary | |
| Feature | speed_mph (mph) |
| Feature | grade_percent (percent) |
| Feature | turn_angle (degrees) |
| Distance | distance (miles) |
| Target | gge (gallons gasoline) |
| Predicted Consumption | 30.364 (miles/gallons gasoline) |
| Real World Predicted Consumption | 26.041 (miles/gallons gasoline) |
| Predict Method | RATE |
Now, let's predict energy consumption over a sample route. RouteE Powertrain expects the inputs to be a pandas dataframe in which each row represents a road network link. There is a sample route included with the package that we'll use for demonstration.
sample_route = pt.load_sample_route()
sample_route
| speed_mph | grade_percent | distance | |
|---|---|---|---|
| 0 | 7.632068 | -0.896343 | 0.015469 |
| 1 | 6.329613 | -4.700083 | 0.003516 |
| 2 | 12.248512 | 0.000000 | 0.003402 |
| 3 | 23.752604 | -0.046280 | 0.019768 |
| 4 | 46.024926 | -0.464073 | 0.038378 |
| ... | ... | ... | ... |
| 120 | 7.415272 | -0.133898 | 0.006128 |
| 121 | 27.685268 | -3.074826 | 0.023170 |
| 122 | 51.322545 | -0.848964 | 0.028510 |
| 123 | 50.431920 | -1.053289 | 0.028015 |
| 124 | 48.325893 | -1.758078 | 0.040274 |
125 rows × 3 columns
If we just pass in the links DataFrame without any other information, the model will assume we want to use all the features and in this case will look for an internal estimator with features to match all the columns.
Based on the model summary shown above, we do have an estimator that takes in the link features speed_mph and grade_percent with a distance of distance and so it will automatically select that estimator when we predict.
camry.predict(sample_route)
| gge | |
|---|---|
| 0 | 0.001028 |
| 1 | 0.000252 |
| 2 | 0.000174 |
| 3 | 0.000995 |
| 4 | 0.001056 |
| ... | ... |
| 120 | 0.000411 |
| 121 | 0.000769 |
| 122 | 0.000731 |
| 123 | 0.000719 |
| 124 | 0.000886 |
125 rows × 1 columns
If we want to use a different estimator, we can tell the predict method to only use a subset of the features. In this case, we'll tell the model to only use speed.
camry.predict(sample_route, feature_columns=["speed_mph"])
| gge | |
|---|---|
| 0 | 0.001095 |
| 1 | 0.000281 |
| 2 | 0.000185 |
| 3 | 0.000967 |
| 4 | 0.001145 |
| ... | ... |
| 120 | 0.000442 |
| 121 | 0.001043 |
| 122 | 0.000851 |
| 123 | 0.000836 |
| 124 | 0.001202 |
125 rows × 1 columns
Model Visualization#
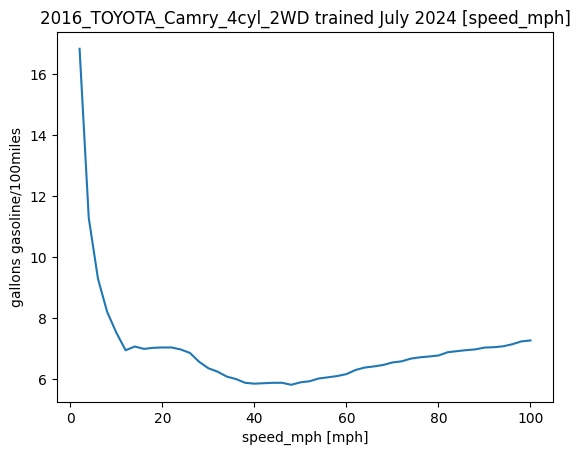
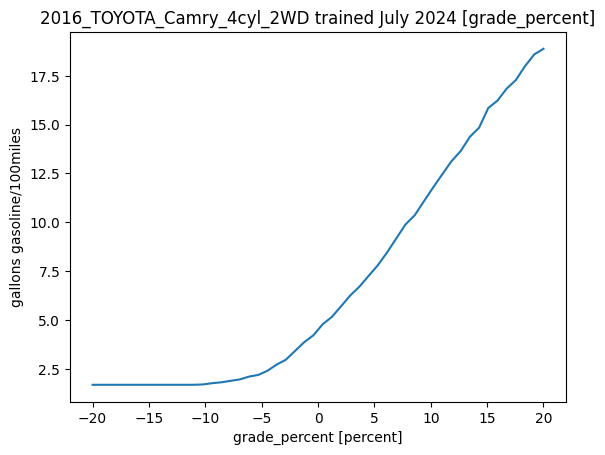
There are a few different functions we can visualize what a model is predicting over a range of inputs.
The first is the visualize_features function that sweeps a feature over a range and plots the results.
In order to use this we first have to define what ranges the features should be considered.
feature_ranges = {
"speed_mph": {"lower": 2, "upper": 100, "n_samples": 50},
"grade_percent": {"lower": -20.0, "upper": 20.0, "n_samples": 50}
}
results = pt.visualize_features(camry, feature_ranges)
<Figure size 640x480 with 0 Axes>
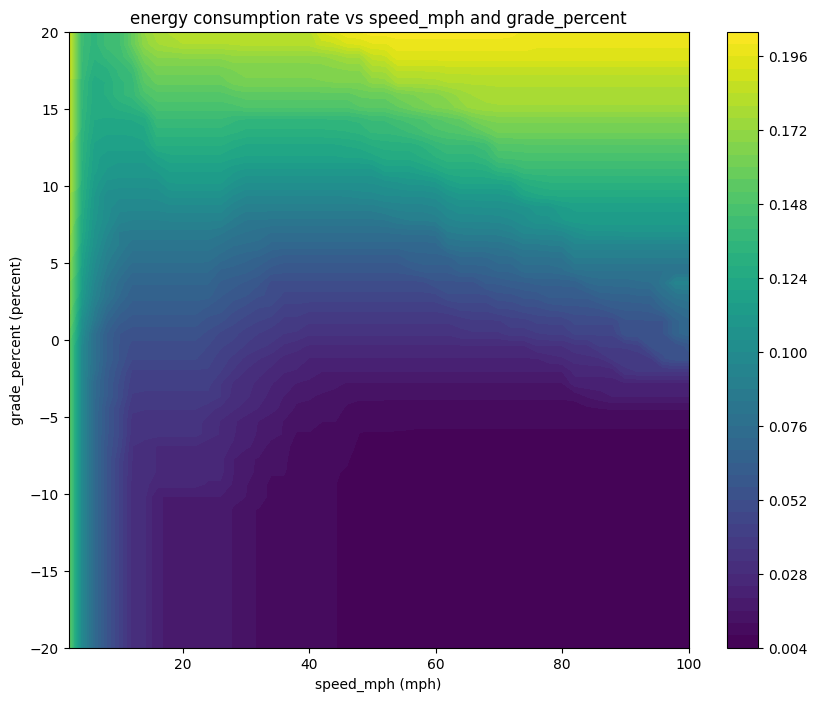
We can also look at two features simultaneously with the contour_plot function.
pt.contour_plot(camry, x_feature="speed_mph", y_feature="grade_percent", feature_ranges=feature_ranges)