Standoff Monte Carlo#
See Monte Carlo - Arrhenius Degredation for a more in depth guide. Steps will be shortened for brevity. This journal applies a Monte Carlo to the Standoff Calculation
# if running on google colab, uncomment the next line and execute this cell to install the dependencies and prevent "ModuleNotFoundError" in later cells:
# !pip install pvdeg
import pvlib
import numpy as np
import pandas as pd
import json
import pvdeg
import matplotlib.pyplot as plt
# This information helps with debugging and getting support :)
import sys
import platform
print("Working on a ", platform.system(), platform.release())
print("Python version ", sys.version)
print("Pandas version ", pd.__version__)
print("Pvlib version ", pvlib.__version__)
print("Pvdeg version ", pvdeg.__version__)
Working on a Linux 6.11.0-1018-azure
Python version 3.11.14 (main, Oct 10 2025, 01:03:14) [GCC 13.3.0]
Pandas version 2.3.3
Pvlib version 0.13.1
Pvdeg version 0.1.dev1+g25fa88ae5
Simple Standoff Calculation#
This is copied from another tutorial called 4 - Standards.ipynb, please visit this page for a more in depth explanation of the process for a single standoff calculation.
# Load weather data from locally saved files to avoid API rate limits
WEATHER = pd.read_csv("../data/psm4_nyc.csv", index_col=0, parse_dates=True)
with open("../data/meta_nyc.json", "r") as f:
META = json.load(f)
# To use the NSRDB API instead, uncomment the lines below and add your API key
# Get your API key at: https://developer.nrel.gov/signup/
# weather_db = "PSM4"
# weather_id = (40.633365593159226, -73.9945801019899) # Manhattan, NYC
# weather_arg = {
# "api_key": "YOUR_API_KEY",
# "email": "user@mail.com",
# "map_variables": True,
# }
# WEATHER, META = pvdeg.weather.get(weather_db, weather_id, **weather_arg)
# simple standoff calculation
height1 = pvdeg.standards.standoff(weather_df=WEATHER, meta=META)
# more arguments standoff calculation
height2 = pvdeg.standards.standoff(
weather_df=WEATHER,
meta=META,
tilt=None,
azimuth=180,
sky_model="isotropic",
temp_model="sapm",
x_0=6.1,
wind_factor=0.33, # default
)
print(height1)
print(height2)
The array surface_tilt angle was not provided, therefore the latitude of 40.6 was used.
The array azimuth was not provided, therefore an azimuth of 180.0 was used.
The array surface_tilt angle was not provided, therefore the latitude of 40.6 was used.
x T98_0 T98_inf
0 0.522443 71.778148 48.754265
x T98_0 T98_inf
0 0.490293 71.778148 48.754265
Defining Correlation Coefficients, Mean and Standard Deviation For Monte Carlo Simulation#
We will leave the list of correlations blank because our variables are not correlated. For a correlated use case visit the Monte Carlo - Arrhenius.ipynb tutorial.
Mean and standard deviation must always be populated if being used to create a dataset. However, you can feed your own correlated or uncorrelated data into the simulate function but column names must be consistent.
# These numbers may not make sense in the context of the problem but work for demonstraiting the process
stats = {"X_0": {"mean": 5, "stdev": 3}, "wind_factor": {"mean": 0.33, "stdev": 0.5}}
corr_coeff = []
samples = pvdeg.montecarlo.generateCorrelatedSamples(corr_coeff, stats, 500)
print(samples)
X_0 wind_factor
0 2.621905 0.182699
1 -0.155672 0.466237
2 2.888131 0.521454
3 5.956088 1.544551
4 2.577917 0.366486
.. ... ...
495 7.599369 -0.149063
496 6.499046 0.469731
497 5.187625 0.464210
498 2.075401 0.386871
499 -2.083049 0.365401
[500 rows x 2 columns]
Standoff Monte Carlo Inputs#
When using the pvdeg.montecarlo.simulate() function on a target function all of the target function’s required arguments must still be given. Our non-changing arguments will be stored in a dictionary. The randomized monte carlo input data will also be passed to the target function via the simulate function. All required target function arguments should be contained between the column names of the randomized input data and fixed argument dictionary,
# defining arguments to pass to the target function, standoff() in this case
function_kwargs = {
"weather_df": WEATHER,
"meta": META,
"azimuth": 180,
"tilt": 0,
"temp_model": "sapm",
"sky_model": "isotropic",
"conf_0": "insulated_back_glass_polymer",
"conf_inf": "open_rack_glass_polymer",
"T98": 70,
"irradiance_kwarg": {},
"conf_0_kwarg": {},
"conf_inf_kwarg": {},
"model_kwarg": {},
}
# notice how we left off parts we want to use in the monte carlo simulation because they are already contained in the dataframe
results = pvdeg.montecarlo.simulate(
func=pvdeg.standards.standoff,
correlated_samples=samples,
**function_kwargs,
)
Dealing With Series#
Notice how our results are contained in a pandas series instead of a dataframe.
This means we have to do an extra step to view our results. Run the block below to confirm that our results are indeed contained in a series. And convert them into a simpler dataframe.
print(type(results))
# Convert from pandas Series to pandas DataFrame
results_df = pd.concat(results.tolist()).reset_index(drop=True)
<class 'pandas.core.series.Series'>
print(results_df)
x T98_0 T98_inf
0 0.145433 71.198899 48.979796
1 0.012157 68.266642 46.925381
2 0.000000 67.638826 46.401058
3 0.000000 46.829346 35.426679
4 0.000000 69.277934 47.630760
.. ... ... ...
495 1.372659 73.840082 50.602662
496 0.000000 68.232791 46.895884
497 0.000000 68.286212 46.942451
498 0.000000 69.004264 47.552714
499 0.067212 69.290027 47.639305
[500 rows x 3 columns]
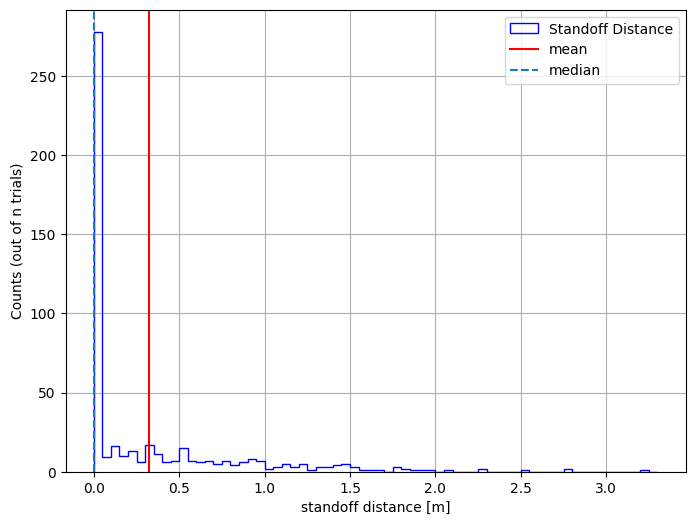
Viewing Our Data#
Let’s plot the results using a histogram
bin_edges = np.arange(results_df["x"].min(), results_df["x"].max() + 0.1, 0.05)
plt.figure(figsize=(8, 6))
plt.hist(
results_df["x"],
bins=bin_edges,
edgecolor="blue",
histtype="step",
linewidth=1,
label="Standoff Distance",
)
plt.ylabel("Counts (out of n trials)")
plt.xlabel("standoff distance [m]")
plt.axvline(np.mean(results_df["x"]), color="red", label="mean")
plt.axvline(np.median(results_df["x"]), linestyle="--", label="median")
plt.legend()
plt.grid(True)
plt.show()