Advanced Usage¶
This section will show how to create customized JADE extensions.
JADE is a framework for running executable computer programs in parallel. Generically, any type of scientific simulation, analysis, or computing jobs, like Python, R, C++, Java, Bash, etc., can be automated and deployed on both personal computer and HPC. When talking about parallelization in Python, normally three modules make the commitments.
threading - https://docs.python.org/3/library/threading.html
multiprocessing - https://docs.python.org/3.7/library/multiprocessing.html
subprocess - https://docs.python.org/3.7/library/subprocess.html
Here, JADE manages parallelization by using subprocess - a Python module. It basically is a wrapper
around os.fork() and os.execve() supporting other executables.
How does JADE work?
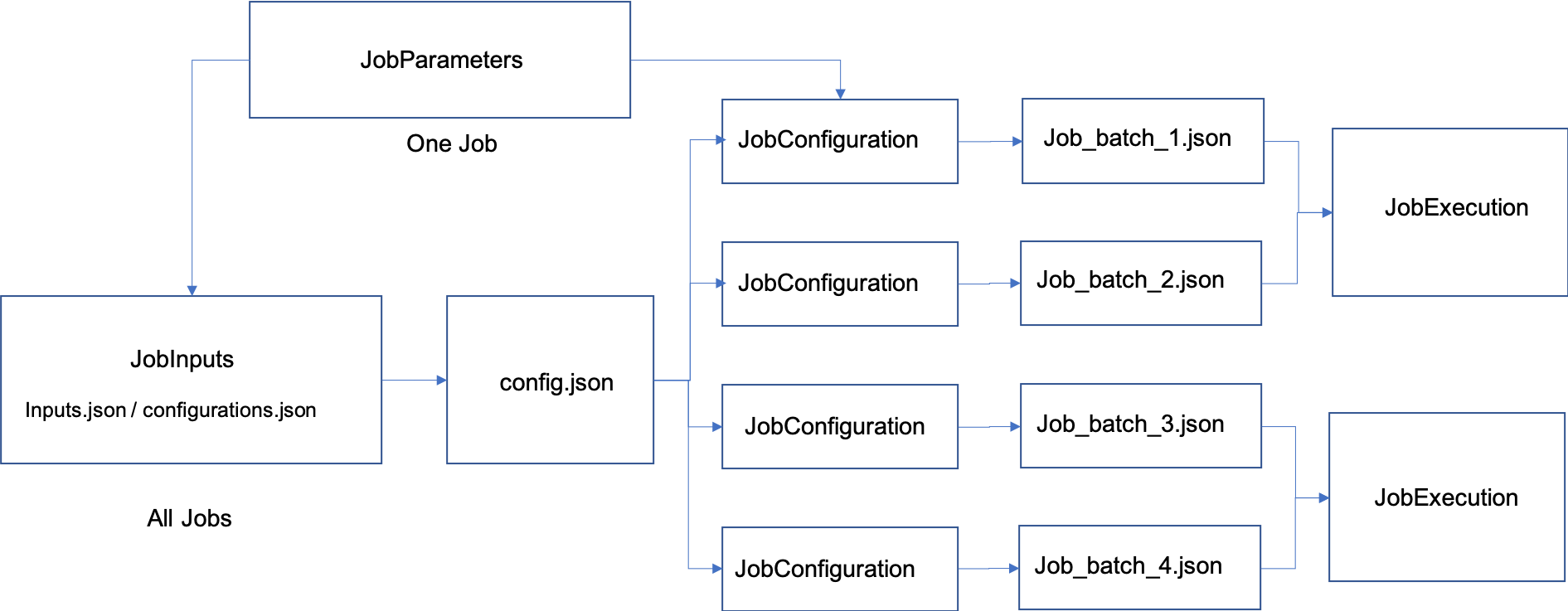
Extending JADE¶
JADE could be extended to support any type of jobs. In JADE, four abstract base classes (ABCs) are defined for extending, as below:
JobParametersInterface: Defines the attributes of a job.JobInputsInterface: Defines the available input parameters for all jobs.JobConfiguration: Defines a batch of jobs to be executed.JobExecutionInterface: Code to run a job.
ABCs behaves same as interface - a term used often in other languages, like Java. In each interface, there are one or more abstract methods declared, but without implementation. These classes could not be instantiated, and need subclasses to provide implementations.
In [1]: from abc import ABC, abstractmethod
In [2]: class A(ABC):
...: @abstractmethod
...: def run(self):
...: pass
...:
In [3]: a = A()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-6-7f181d8f00b8> in <module>
----> 1 a = A()
TypeError: Cannot instantiate abstract class A with abstract methods run
In [4]: class B(A):
...: def run(self):
...: print("Hello World")
...:
In [5]: b = B()
In [6]: b.run()
Hello World
For more details about ABCs, please refer to https://docs.python.org/3/library/abc.html
Generic Command Extension¶
JADE implements an extension called generic_command. You can simply pass a
text file with a list of commands to execute and JADE will run them in parallel.
Example:
$ jade config create commands.txt -c config.json
$ jade submit-jobs config.json
Job Ordering¶
Each job defines a blocked_by field. If you want to guarantee that job ID 6 doesn’t run until job ID 5 completes then add that ID to the field.
{
"command": "<job_cli_command>",
"job_id": 6,
"blocked_by": [5]
}
Demo Extension¶
This section will show you how to create an extension of JADE through implementing abstract methods defined in JADE interfaces, and run a Python data analysis program in parallel.
1. An Auto-regression Analysis Program¶
Suppose we have a series of United States’s GDP data, 1960-2018, named united_states.csv:
year,gdp
1960,543300000000
1961,563300000000
1962,605100000000
...
2000,10252345464000
2001,10581821399000
...
2016,18707188235000
2017,19485393853000
2018,20494100000000
Base on this dataset, we have developed an auto-regression model with validation and plot.
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.ar_model import AR
def autoregression_analysis(country, data, output):
"""
Country based GDP auto-regression analysis
Parameters
----------
country: str
the name of a country
data: str
path to the csv file containing the GDP data.
output: str
The path to the output directory
Returns
-------
tuple, The path of csv result file, and the path of png plot file.
"""
# Read csv
df = pd.read_csv(data, index_col="year")
df = df.dropna()
# Train model
train = df["gdp"].values
model = AR(train)
model_fit = model.fit()
# Validate model
lag = model_fit.k_ar
pred = model_fit.predict(start=lag, end=len(train), dynamic=False)
# Save result
df["pred_gdp"] = [np.nan for _ in range(lag-1)] + list(pred)
result_file = os.path.join(output, os.path.basename(data))
df.to_csv(result_file)
# Save plot
df.plot()
plt.grid(axis="y", linestyle="--")
plt.title(country + "(current $)")
plot_file = os.path.join(output, os.path.basename(data).replace("csv", "png"))
plt.savefig(plot_file)
return result_file, plot_file
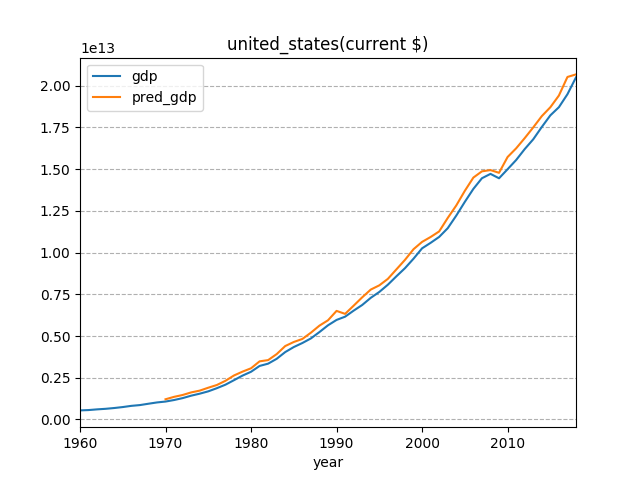
The data columns in result file look like below,
year,gdp,pred_gdp
1960,543300000000,
1961,563300000000,
1962,605100000000,
...
2000,10252345464000,10638026901321.785
2001,10581821399000,10932063383291.346
...
2016,18707188235000,19406250376876.492
2017,19485393853000,20519007253667.656
2018,20494100000000,20672861935684.523
The result data plots are shown as below,
2. Auto-regression Analysis for Many Countries¶
The auto-regression analysis works good for United States, and we want to apply it many more countries, including Australia, Brazil, Canada, China, France, Germany, India, Italy, Japan, Russia, United Kingdom.
The first solution comes in mind may be a Python for loop, like this:
countries = [
"Australia", "Brazil", "Canada",
"China", "France", "Germany",
"India", "Italy", "Japan",
"Russia", "United Kingdom", "United States"
]
data = [
"data/gdp/countries/austrilia.csv",
"data/gdp/countries/brazil.csv",
"data/gdp/countries/canada.csv",
"data/gdp/countries/china.csv",
"data/gdp/countries/france.csv",
"data/gdp/countries/germany.csv",
"data/gdp/countries/india.csv",
"data/gdp/countries/italy.csv",
"data/gdp/countries/japan.csv",
"data/gdp/countries/russia.csv",
"data/gdp/countries/united_kingdom.csv",
"data/gdp/countries/united_states.csv",
]
for i, country in enumerate(countries):
autoregression_analysis(country, data[i], output)
There is no problem with just a few countries, and each analysis runs a short time. However, how about
if these are countries of our world? how about if a
program runs one hour or longer? for loop might not be a good solution.
Alternatively, we need to figure out how to run autoregression_analysis in parallel.
3. Create Extension by Extending JADE¶
To extend JADE is to implement its abstract methods defined in JADE interface
classes based on your scenario. All abstract methods should be overwritten by concrete methods. If
you don’t think the method is necessary for you, then just pass in the implementation.
JobParametersInterface: Defines the attributes of an auto-regression job.
class AutoRegressionParameters(JobParametersInterface):
"""
A class used for creating auto-regression job.
"""
...
Please check the source code jade.extensions.demo.autoregression_paramters.
JobInputsInterface: Defines the available input parameters for all aut-regression jobs.
class AutoRegressionInputs(JobInputsInterface):
"""
A class used for configuring auto-regression analysis jobs.
"""
INPUTS_FILE = "inputs.json"
...
Please check the source code jade.extensions.demo.autoregression_inputs.
Note
It’s the user’s responsibility to generate the inputs.json file that would be
consumed by this class. For this demo extension, there’s a script file used for creating
the json file. In this demo, the inputs.json was created using this Python
script.
JobConfiguration: Defines a batch of auto-regression jobs to be executed.
class AutoRegressionConfiguration(JobConfiguration):
"""
A class used to configure auto-regression jobs
"""
...
JobExecutionInterface: Code to run a auto-regression job.
Please checkout the source code jade.extensions.demo.autoregression_configuration.
class AutoRegressionExecution(JobExecutionInterface):
"""
A class used for auto-regression job execution on computer.
"""
...
Please checkout the source code jade.extensions.demo.autoregression_execution
4. Register Your Extension in JADE¶
All extensions created by users have to be registered so that JADE can recognize it. In JADE, it uses
jade.extensions.registry.py file to register the extensions.
To register demo extension, add the followings to EXTENSION_REGISTRY dictionary.
Extension name
demoas the key.Job execution class, that is,
demo.autoregression_execution.AutoRegressionExecution.Job configuration class, that is,
demo.autoregression_configuration.AutoRegressionConfiguration.
5. Create Functions Consumed by CLI¶
JADE provides consistent CLI commands for all extensions, to enable your extension
to run using JADE CLI. Two functions auto-config,
run in cli.py module should be implemented with exact names defined here.
For demo extension, the auto_config and run functions looks like this,
def auto_config(inputs):
"""
Create a configuration file for demo
:param inputs: str, the path to directory containing autoregression data.
:return: None
"""
...
def run(config_file, name, output, output_format, verbose):
"""Run auto regression analysis through command line"""
...
Please check the source code jade.extensions.demo.cli.
Those two functions are consumed by JADE’s CLI commands jade auto-config and
jade submit-jobs separately in command line.
6. Make a Robust Extension via Test¶
Good unit tests and integration tests can make your JADE extension to be robust. Here, JADE uses Pytest framework - https://docs.pytest.org/en/latest/ to perform unit tests and integration tests.
Here are some examples for demo extensions.
The following is an unit test from tests.unit.extensions.demo.test_autregression_execution.py.
@patch("jade.extensions.demo.autoregression_execution.autoregression_analysis")
def test_run(mock_autoregression_analysis):
"""Should call the autoregerssion_analysis method defined outside of class"""
job = MagicMock()
job.country = "united_states"
job.data = "data.csv"
output = os.path.join(tempfile.gettempdir(), "jade-unit-test-output")
mock_autoregression_analysis.side_effect = run_autoregression_analysis
are = AutoRegressionExecution(job, output)
are.run()
mock_autoregression_analysis.assert_called_once()
mock_autoregression_analysis.assert_called_with(
country="united_states",
data="data.csv",
output=os.path.join(tempfile.gettempdir(), "jade-unit-test-output")
)
shutil.rmtree(output)
The following is an integration test from tests.integration.extensions.demo.test_auto_config.py.
import os
import pytest
from jade.utils.subprocess_manager import run_command
@pytest.fixture
def test_data_dir():
"""The path to the directory that contains the fixture data"""
return os.path.join(os.path.dirname(__file__), "data")
def test_auto_config(test_data_dir):
"""Should create a config.json file"""
inputs = os.path.join(test_data_dir, "demo")
config_file = os.path.join(inputs, "config.json")
if os.path.exists(config_file):
os.remove(config_file)
# run command
cmd = "jade auto-config demo {} -c {}".format(inputs, config_file)
returncode = run_command(cmd=cmd)
assert returncode == 0
assert os.path.exists(config_file)
# check result
data = load_data(config_file)
assert "jobs" in data
assert len(data["jobs"]) == 3
Check the coverage of the unit tests. Normally, the unit test cases should cover more than 90% of the code.
$ pytest --cov=jade/extensions/demo/ tests/unit/extensions/demo
===================================================================================== test session starts =====================================================================================
platform darwin -- Python 3.7.4, pytest-5.1.2, py-1.8.0, pluggy-0.12.0
rootdir: /Users/jgu2/Workspace/jade
plugins: cov-2.7.1
collected 35 items
tests/unit/extensions/demo/test_autogression_execution.py ...... [ 17%]
tests/unit/extensions/demo/test_autoregression_configuration.py ................... [ 71%]
tests/unit/extensions/demo/test_autoregression_inputs.py ... [ 80%]
tests/unit/extensions/demo/test_autoregression_parameters.py ..... [ 94%]
tests/unit/extensions/demo/test_cli.py .. [100%]
---------- coverage: platform darwin, python 3.7.4-final-0 -----------
Name Stmts Miss Cover
---------------------------------------------------------------------------
jade/extensions/demo/__init__.py 0 0 100%
jade/extensions/demo/autoregression_configuration.py 17 0 100%
jade/extensions/demo/autoregression_execution.py 53 2 96%
jade/extensions/demo/autoregression_inputs.py 21 0 100%
jade/extensions/demo/autoregression_parameters.py 23 1 96%
jade/extensions/demo/cli.py 19 1 95%
---------------------------------------------------------------------------
TOTAL 133 4 97%
Please refer to Pytest https://docs.pytest.org/en/latest/example/index.html to learn more about testing.
7. Try Auto-regression Analysis in Parallel¶
Run the JADE CLI commands at your localhost.
$ jade auto-config demo data
Created configuration with 12 jobs.
Dumped configuration to config.json.
This command line generate the global config.json file with all auto-regression jobs.
$ jade submit-jobs config.json -h hpc_config.toml
2019-10-14 14:35:21,921 - INFO [jade.cli.submit_jobs submit_jobs.py:92] : jade submit-jobs config.json -h /Users/jgu2/Workspace/jade/hpc_config.toml
2019-10-14 14:35:22,160 - INFO [jade.jobs.job_submitter job_submitter.py:166] : Submit 12 jobs for execution.
2019-10-14 14:35:22,160 - INFO [jade.jobs.job_submitter job_submitter.py:167] : JADE version 0.1.0
2019-10-14 14:35:22,177 - INFO [jade.utils.repository_info repository_info.py:95] : Wrote diff to output/diff.patch
2019-10-14 14:35:22,228 - INFO [jade.jobs.job_runner job_runner.py:56] : Run jobs.
2019-10-14 14:35:22,228 - INFO [jade.jobs.job_runner job_runner.py:106] : Created jade scratch_dir=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a
2019-10-14 14:35:22,231 - INFO [jade.jobs.job_runner job_runner.py:147] : Generated 12 jobs to execute on 12 workers max=12.
2019-10-14 14:35:24,059 - INFO [demo run.py:66] : jade run demo --name=australia --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,060 - INFO [demo run.py:66] : jade run demo --name=brazil --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,091 - INFO [demo run.py:66] : jade run demo --name=china --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,093 - INFO [demo run.py:66] : jade run demo --name=canada --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,110 - INFO [demo run.py:66] : jade run demo --name=france --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,146 - INFO [demo run.py:66] : jade run demo --name=germany --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,162 - INFO [demo run.py:66] : jade run demo --name=india --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,181 - INFO [demo run.py:66] : jade run demo --name=japan --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,187 - INFO [demo run.py:66] : jade run demo --name=italy --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,234 - INFO [demo run.py:66] : jade run demo --name=russia --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,237 - INFO [demo run.py:66] : jade run demo --name=united_kingdom --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:24,265 - INFO [demo run.py:66] : jade run demo --name=united_states --output=output/job-outputs --config-file=./jade-a021254e-4620-4b29-a21a-bbd3448c2f5a/config.json
2019-10-14 14:35:25,395 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job australia completed return_code=0 exec_time_s=3.161540985107422 filename=output/results/australia_20191014_143522_batch_0.toml
2019-10-14 14:35:25,396 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job brazil completed return_code=0 exec_time_s=3.153259038925171 filename=output/results/brazil_20191014_143522_batch_0.toml
2019-10-14 14:35:25,398 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job canada completed return_code=0 exec_time_s=3.1425909996032715 filename=output/results/canada_20191014_143522_batch_0.toml
2019-10-14 14:35:26,399 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job china completed return_code=0 exec_time_s=4.13318395614624 filename=output/results/china_20191014_143522_batch_0.toml
2019-10-14 14:35:26,400 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job france completed return_code=0 exec_time_s=4.124361991882324 filename=output/results/france_20191014_143522_batch_0.toml
2019-10-14 14:35:26,401 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job germany completed return_code=0 exec_time_s=4.114736080169678 filename=output/results/germany_20191014_143522_batch_0.toml
2019-10-14 14:35:26,401 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job india completed return_code=0 exec_time_s=4.1038658618927 filename=output/results/india_20191014_143522_batch_0.toml
2019-10-14 14:35:26,402 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job italy completed return_code=0 exec_time_s=4.092925786972046 filename=output/results/italy_20191014_143522_batch_0.toml
2019-10-14 14:35:26,402 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job japan completed return_code=0 exec_time_s=4.082369089126587 filename=output/results/japan_20191014_143522_batch_0.toml
2019-10-14 14:35:26,403 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job russia completed return_code=0 exec_time_s=4.070515871047974 filename=output/results/russia_20191014_143522_batch_0.toml
2019-10-14 14:35:26,403 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job united_kingdom completed return_code=0 exec_time_s=4.047858953475952 filename=output/results/united_kingdom_20191014_143522_batch_0.toml
2019-10-14 14:35:26,404 - INFO [jade.jobs.dispatchable_job dispatchable_job.py:57] : Job united_states completed return_code=0 exec_time_s=4.033797025680542 filename=output/results/united_states_20191014_143522_batch_0.toml
2019-10-14 14:35:27,404 - INFO [jade.jobs.job_runner job_runner.py:156] : Jobs are complete. count=12
2019-10-14 14:35:27,423 - INFO [jade.jobs.job_runner job_runner.py:95] : Wrote summary of job batch to output/results/results_20191014_143522_batch_0_summary.toml
2019-10-14 14:35:27,424 - INFO [jade.jobs.job_runner job_runner.py:70] : Completed 12 jobs
2019-10-14 14:35:27,426 - INFO [jade.utils.timing_utils timing_utils.py:34] : execution-time=5.198 s func=run_jobs
2019-10-14 14:35:27,480 - INFO [jade.jobs.job_submitter job_submitter.py:214] : Wrote results to output/results.json.
2019-10-14 14:35:27,481 - INFO [jade.jobs.job_submitter job_submitter.py:220] : Successful=12 Failed=0 Total=12
All job results are saved into output directory. To check the results,
$ jade show-results
Results from directory: output
JADE Version: 0.1.0
10/14/2019 14:35:27
+----------------+-------------+----------+--------------------+
| Job Name | Return Code | Status | Execution Time (s) |
+----------------+-------------+----------+--------------------+
| japan | 0 | finished | 4.082369089126587 |
| china | 0 | finished | 4.13318395614624 |
| united_states | 0 | finished | 4.033797025680542 |
| india | 0 | finished | 4.1038658618927 |
| russia | 0 | finished | 4.070515871047974 |
| france | 0 | finished | 4.124361991882324 |
| germany | 0 | finished | 4.114736080169678 |
| italy | 0 | finished | 4.092925786972046 |
| australia | 0 | finished | 3.161540985107422 |
| brazil | 0 | finished | 3.153259038925171 |
| canada | 0 | finished | 3.142590999603271 |
| united_kingdom | 0 | finished | 4.047858953475952 |
+----------------+-------------+----------+--------------------+
Num successful: 12
Num failed: 0
Total: 12
Avg execution time (s): 3.86
Min execution time (s): 3.14
Max execution time (s): 4.13
8. Run Your Extension on HPC¶
Pull the JADE source code, and setup the jade conda environment on HPC, then
run the CLI commands to parallelize the auto-regression analysis.
Auto-config auto-regression jobs and create a config.json.
$ jade auto-config demo data
Created configuration with 12 jobs.
Dumped configuration to config.json.
Submit auto-regression jobs, and wait for program to finish.
$ jade submit-jobs config.json -h hpc_config.toml
2019-10-16 13:50:03,212 - INFO [jade.cli.submit_jobs submit_jobs.py:92] : jade submit-jobs config.json -h /home/jgu2/Workspace/jade/hpc_config.toml
2019-10-16 13:50:03,843 - INFO [jade.jobs.job_submitter job_submitter.py:166] : Submit 12 jobs for execution.
2019-10-16 13:50:03,843 - INFO [jade.jobs.job_submitter job_submitter.py:167] : JADE version 0.1.0
2019-10-16 13:50:03,903 - INFO [jade.utils.repository_info repository_info.py:98] : No diff detected in repository.
2019-10-16 13:50:03,978 - INFO [jade.jobs.job_submitter job_submitter.py:285] : Created split config file output/config_batch_1.json with 12 jobs
2019-10-16 13:50:03,980 - INFO [jade.utils.utils utils.py:58] : Writing output/run_batch_1.sh
2019-10-16 13:50:03,995 - INFO [jade.hpc.slurm_manager slurm_manager.py:83] : stripe_count is set to 16
2019-10-16 13:50:03,997 - INFO [jade.utils.utils utils.py:58] : Writing output/job_batch_1.sh
2019-10-16 13:50:03,998 - INFO [jade.hpc.hpc_manager hpc_manager.py:135] : Created submission script output/job_batch_1.sh
2019-10-16 13:50:04,033 - INFO [jade.hpc.hpc_manager hpc_manager.py:140] : job 'job_batch_1' with ID=1536598 submitted successfully
2019-10-16 13:50:04,033 - INFO [jade.hpc.hpc_manager hpc_manager.py:262] : Assigned job_ID=1536598 name=job_batch_1
2019-10-16 13:50:04,057 - INFO [jade.hpc.hpc_manager hpc_manager.py:242] : Submission job_batch_1 1536598 changed status from HpcJobStatus.NONE to HpcJobStatus.QUEUED
2019-10-16 13:50:36,121 - INFO [jade.hpc.hpc_manager hpc_manager.py:242] : Submission job_batch_1 1536598 changed status from HpcJobStatus.QUEUED to HpcJobStatus.NONE
2019-10-16 13:51:06,151 - INFO [jade.jobs.job_submitter job_submitter.py:314] : All submitters have completed.
2019-10-16 13:51:06,330 - INFO [jade.jobs.job_submitter job_submitter.py:214] : Wrote results to output/results.json.
2019-10-16 13:51:06,330 - INFO [jade.jobs.job_submitter job_submitter.py:220] : Successful=12 Failed=0 Total=12
Check the job results, all desired results are generated.
$ ls -lh output/job-outputs/
total 580K
-rw-rw----. 1 user user 2.2K Oct 16 13:50 australia.csv
-rw-rw----. 1 user user 31K Oct 16 13:50 australia.png
-rw-rw----. 1 user user 157 Oct 16 13:50 australia_summary.toml
-rw-rw----. 1 user user 2.2K Oct 16 13:50 brazil.csv
-rw-rw----. 1 user user 35K Oct 16 13:50 brazil.png
-rw-rw----. 1 user user 145 Oct 16 13:50 brazil_summary.toml
-rw-rw----. 1 user user 2.2K Oct 16 13:50 canada.csv
-rw-rw----. 1 user user 37K Oct 16 13:50 canada.png
-rw-rw----. 1 user user 145 Oct 16 13:50 canada_summary.toml
-rw-rw----. 1 user user 2.2K Oct 16 13:50 china.csv
-rw-rw----. 1 user user 31K Oct 16 13:50 china.png
-rw-rw----. 1 user user 141 Oct 16 13:50 china_summary.toml
-rw-rw----. 1 user user 192 Oct 16 13:50 demo_run_96440.log
-rw-rw----. 1 user user 189 Oct 16 13:50 demo_run_96441.log
-rw-rw----. 1 user user 189 Oct 16 13:50 demo_run_96442.log
-rw-rw----. 1 user user 188 Oct 16 13:50 demo_run_96443.log
-rw-rw----. 1 user user 189 Oct 16 13:50 demo_run_96444.log
-rw-rw----. 1 user user 190 Oct 16 13:50 demo_run_96445.log
-rw-rw----. 1 user user 188 Oct 16 13:50 demo_run_96446.log
-rw-rw----. 1 user user 188 Oct 16 13:50 demo_run_96447.log
-rw-rw----. 1 user user 188 Oct 16 13:50 demo_run_96448.log
-rw-rw----. 1 user user 189 Oct 16 13:50 demo_run_96449.log
-rw-rw----. 1 user user 197 Oct 16 13:50 demo_run_96450.log
-rw-rw----. 1 user user 196 Oct 16 13:50 demo_run_96451.log
-rw-rw----. 1 user user 2.2K Oct 16 13:50 france.csv
-rw-rw----. 1 user user 36K Oct 16 13:50 france.png
-rw-rw----. 1 user user 145 Oct 16 13:50 france_summary.toml
-rw-rw----. 1 user user 1.9K Oct 16 13:50 germany.csv
-rw-rw----. 1 user user 38K Oct 16 13:50 germany.png
-rw-rw----. 1 user user 149 Oct 16 13:50 germany_summary.toml
-rw-rw----. 1 user user 2.2K Oct 16 13:50 india.csv
-rw-rw----. 1 user user 30K Oct 16 13:50 india.png
-rw-rw----. 1 user user 141 Oct 16 13:50 india_summary.toml
-rw-rw----. 1 user user 2.2K Oct 16 13:50 italy.csv
-rw-rw----. 1 user user 35K Oct 16 13:50 italy.png
-rw-rw----. 1 user user 141 Oct 16 13:50 italy_summary.toml
-rw-rw----. 1 user user 2.2K Oct 16 13:50 japan.csv
-rw-rw----. 1 user user 35K Oct 16 13:50 japan.png
-rw-rw----. 1 user user 141 Oct 16 13:50 japan_summary.toml
-rw-rw----. 1 user user 1.2K Oct 16 13:50 russia.csv
-rw-rw----. 1 user user 35K Oct 16 13:50 russia.png
-rw-rw----. 1 user user 145 Oct 16 13:50 russia_summary.toml
-rw-rw----. 1 user user 2.2K Oct 16 13:50 united_kingdom.csv
-rw-rw----. 1 user user 38K Oct 16 13:50 united_kingdom.png
-rw-rw----. 1 user user 177 Oct 16 13:50 united_kingdom_summary.toml
-rw-rw----. 1 user user 2.1K Oct 16 13:50 united_states.csv
-rw-rw----. 1 user user 37K Oct 16 13:50 united_states.png
-rw-rw----. 1 user user 173 Oct 16 13:50 united_states_summary.toml
9. Structured Log Events¶
JADE provides structured log events so that specific conditions or errors can
be machine-parsed and summarized after running jobs. Extensions can implement
their own structured events by passing custom fields to the StructuredLogEvent
or StructuredErrorLogEvent classes and then call log_event.
The CLI command jade show-events can be used to view events after
execution.
The following example shows how to use StructuredLogEvent,
from jade.events import StructuredErrorLogEvent
def run(self):
"""Runs the autoregression, and return status code"""
try:
result_file, plot_file = autoregression_analysis(
country=self._job.country,
data=self._job.data,
output=self._job_dir
)
summary_data = {
"name": self._job.name,
"country": self._job.country,
"output": self._output,
"result": result_file,
"plot": plot_file
}
summary_file = os.path.join(self._job_dir, "summary.toml")
dump_data(summary_data, summary_file)
# Log event into file
except Exception:
# Create event instance
event = StructuredErrorLogEvent(
source=self._job.name,
category=EVENT_CATEGORY_ERROR,
name=EVENT_NAME_UNHANDLED_ERROR,
message="Analysis failed!",
)
# Log event into file with structured message.
log_event(event)
# Must raise the exception here, or job returncode is 0 even it fails.
raise
return 0
The following console output shows demo extension with a job failure.
$ jade show-results
Results from directory: output
JADE Version: 0.1.0
04/29/2020 17:18:23
+---------------+-------------+----------+--------------------+----------------------------+
| Job Name | Return Code | Status | Execution Time (s) | Completion Time |
+---------------+-------------+----------+--------------------+----------------------------+
| australia | 1 | finished | 3.0269670486450195 | 2020-04-29 17:18:22.772346 |
| brazil | 0 | finished | 3.019500732421875 | 2020-04-29 17:18:22.772818 |
| united_states | 0 | finished | 3.014056921005249 | 2020-04-29 17:18:22.773059 |
+---------------+-------------+----------+--------------------+----------------------------+
Num successful: 2
Num failed: 1
Total: 3
Avg execution time (s): 3.02
Min execution time (s): 3.01
Max execution time (s): 3.03
Now, show events using JADE CLI show-events,
$ jade show-events unhandled_error
Events of type unhandled_error from directory: output
+----------------------------+-----------+---------------------------------------------------------+-------+---------------------+-----------------------------+--------+
| timestamp | source | message | error | exception | filename | lineno |
+----------------------------+-----------+---------------------------------------------------------+-------+---------------------+-----------------------------+--------+
| 2020-04-29 17:18:21.708168 | australia | Analysis failed! | test | <class 'Exception'> | autoregression_execution.py | 161 |
| 2020-04-29 17:18:21.709596 | australia | unexpected exception in run 'demo' job=australia - test | test | <class 'Exception'> | run.py | 82 |
+----------------------------+-----------+---------------------------------------------------------+-------+---------------------+-----------------------------+--------+
Based on the structured event logs, the user can track the job execution issue easily.
That’s what we all need to create a JADE extension. Now, you can create your own extension based on JADE, and parallelize your programs. Happy coding!
Post-process¶
A post-process can be attached to an individual job, after the job run finishes, then the post-process startes to run. For example, the post-process can be an analysis program which could be used to run on top of a job outputs.
There are two options to acheive
Use Post-process Class¶
Define Post-process
Suppose you have a package/module in script job.analysis.post_analysis.py,
class PostAnalysis:
"""A class for your post-process"""
def run(self, **kwargs):
# TODO: implement your post-analysis logic
Where a run method is defined in the class.
Auto Config
Define the post-process config file in .toml or .json. For example,
the file ~/my-post-analysis-config.toml is defined below,
class = "PostAnalysis"
module = "job.analysis.post_analysis"
[data]
name = "example"
year = 2000
count = 5
# whatever the data needed to pass to the `run` method
To config the post-process with jobs, use the command below,
$ jade auto-config --job-post-process-config-file ~/my-post-analysis-config.toml
Sumbit Jobs
$ jade submit-jobs config.json
Use Job Ordering¶
Another option is to use job ordering to perform post-processing. You can set
the blocked_by attribute of the post-processing job with the ID of the
main job.
{
"command": "<main-job-cli-cmd>",
"job_id": 1,
"blocked_by": []
},
{
"command": "<post-process-cli-cmd>",
"job_id": 2,
"blocked_by": [1]
}