2024 Workshops Report#
The Holistic Modeling Portfolio Coordination Project hosted a series of workshops in June 2024 to discuss the current state and future direction of the WETO Software Stack. Four individual workshops covering different areas of the WETO Software Stack were held over a span of two weeks. This report summarizes the workshop proceedings and lists key takeaways from each one.
Recordings and workshop materials are listed in the workshop home page.
General Overview#
The WETO Software Stack was divided into sections based on the context in which a software is typically used, and a workshop was held for each section. A map of the software included in each section and workshop is shown shown below.
The workshops were between one and a half to two hours long and generally followed this format:
Duration |
Topic |
|---|---|
5 min |
Welcome and intro |
10 min |
Intro to Portfolio Coordination Project, WETO Software Stack overview |
10-15 min |
WETO Software Stack Q&A |
50 min |
Model introductions, capabilities and workflow demo, future roadmap |
2 min |
Poll on usability issues, voting for roadmap priorities |
30 min |
Community discussion, Q&A |
10 min |
Wrap up, Methods for community engagement |
Model owners from each software project presented on the capabilities, workflows, and future roadmap of their software.
The registration and attendance count for each workshop is plotted below.
Discussion Points#
Takeaways from the discussion portions of the workshops are summarized here. Detailed notes on the discussions are listed in Discussion Notes.
Across all workshops, it was noted that some information on approaching the whole WETO Software Stack to understand which tools to use and how to use them to accomplish a particular task would be helpful. Suggestions for a map on how the software relate to each other and a decision tree to guide users toward choosing a subset of the software stack for their particular needs were made. Related, several attendees commented on the need to improve accessibility. They noted that the documentation is often difficult to read when it exists, and it can be a challenge to find resources like examples or community events if you don’t already know where to look. While examples are appreciated, outdated resources and poorly-designed user flows make them less effective and, at times, increase the barrier to entry.
The need for a common input file structure across the software stack was mentioned in several workshops, and specifically the windIO project was noted as a potential solution. Model owners and attendees largely agreed that adopting this file format would be beneficial to all stakeholders.
Holistic Modeling Project action items and suggestions:
Possibly support windIO directly
Propose unified workflows that integrate the WETO Software Stack with windIO
Formalize the reference turbines into a turbine library described by windIO
Develop guidance on user onboarding documentation and examples
Regular newsletter and online listing of updates and events
Poll Results#
During the workshop discussion sections, the presenters conducted polls of the audience. For the first three workshops, the polling was conducted via the Microsoft Teams Polls app, and Mentimeter was used for the final workshop. The Teams Polls app turned out to be faulty, so many of the results are unreliable. A broad qualitative summary of the results is given here.
User Support#
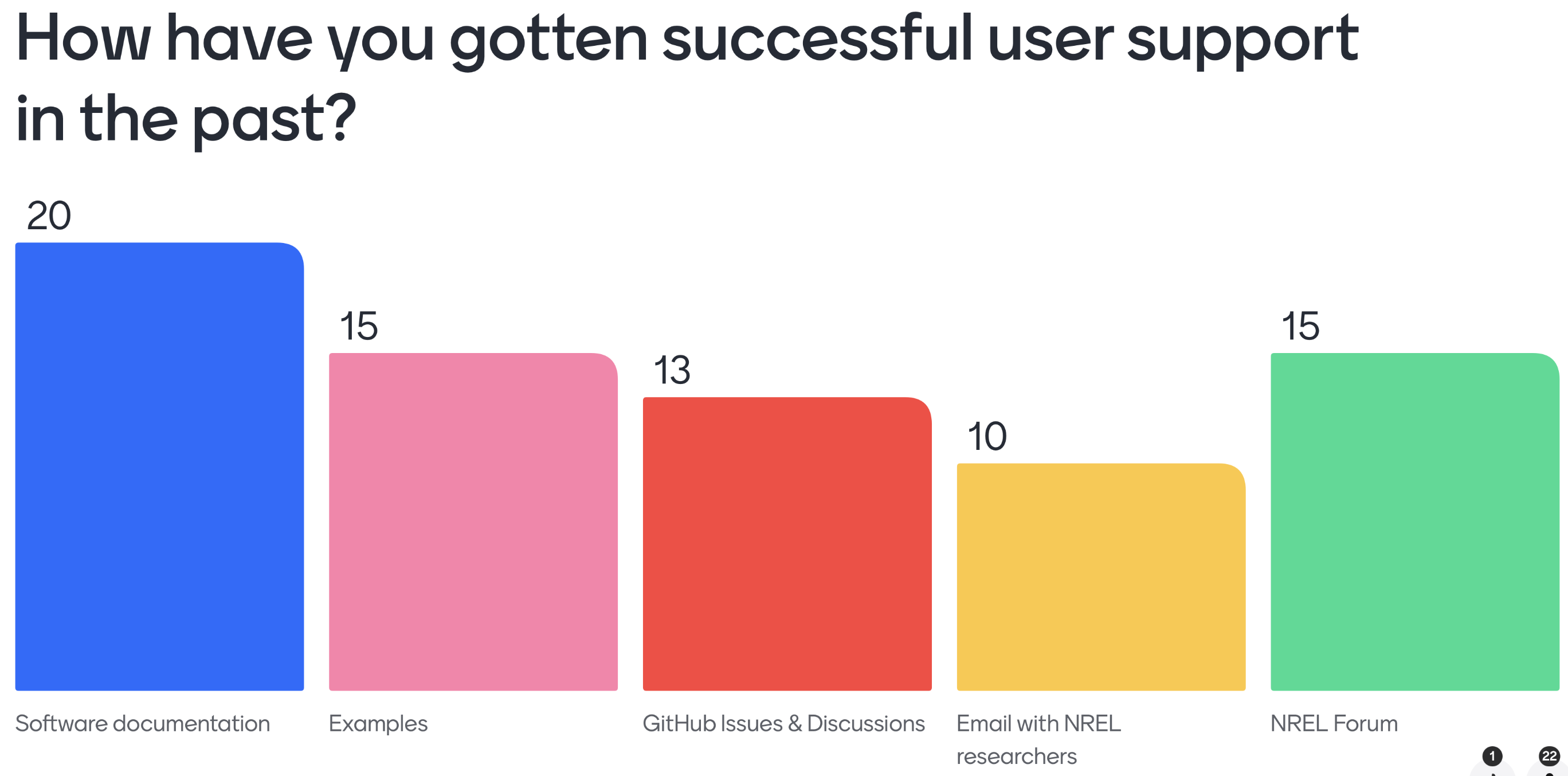
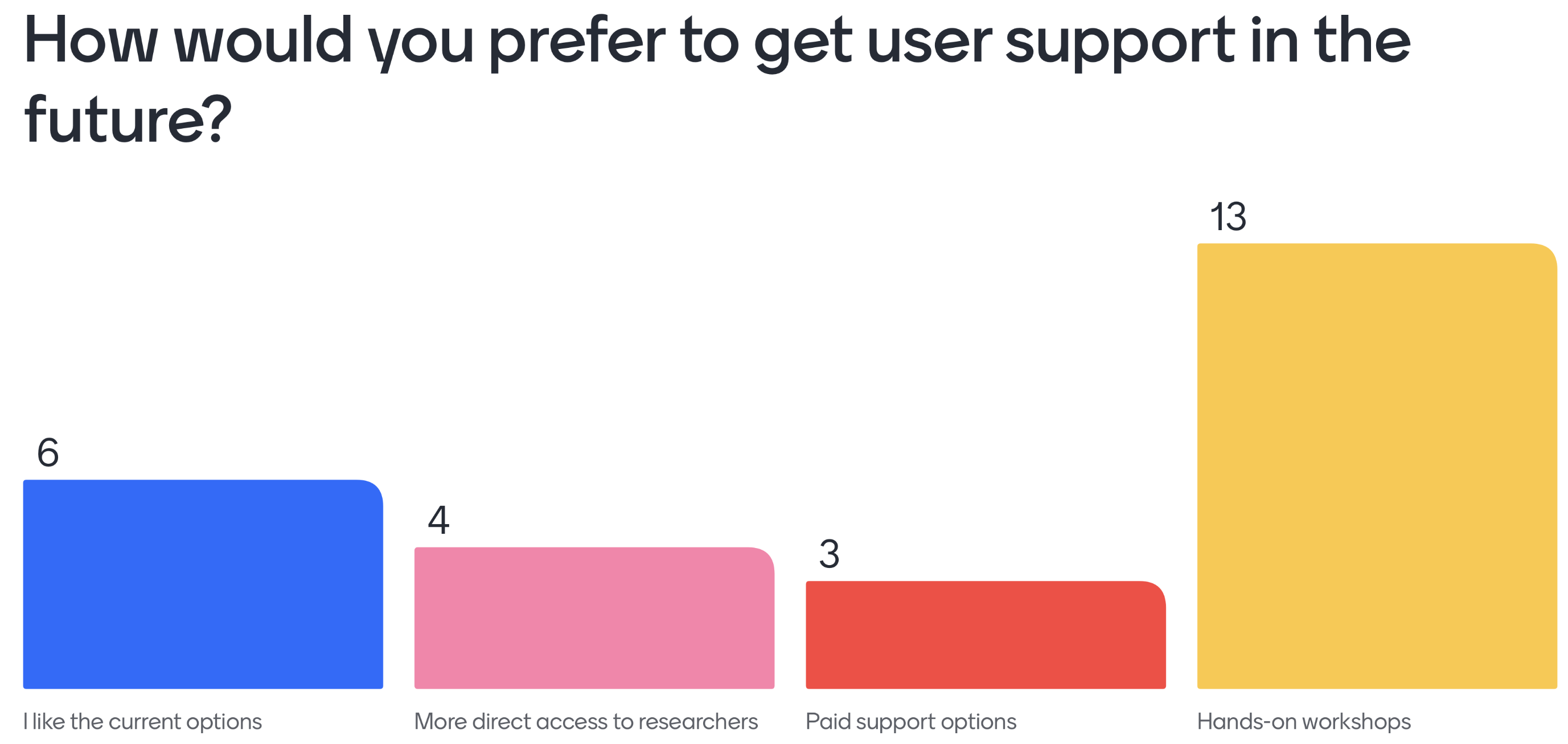
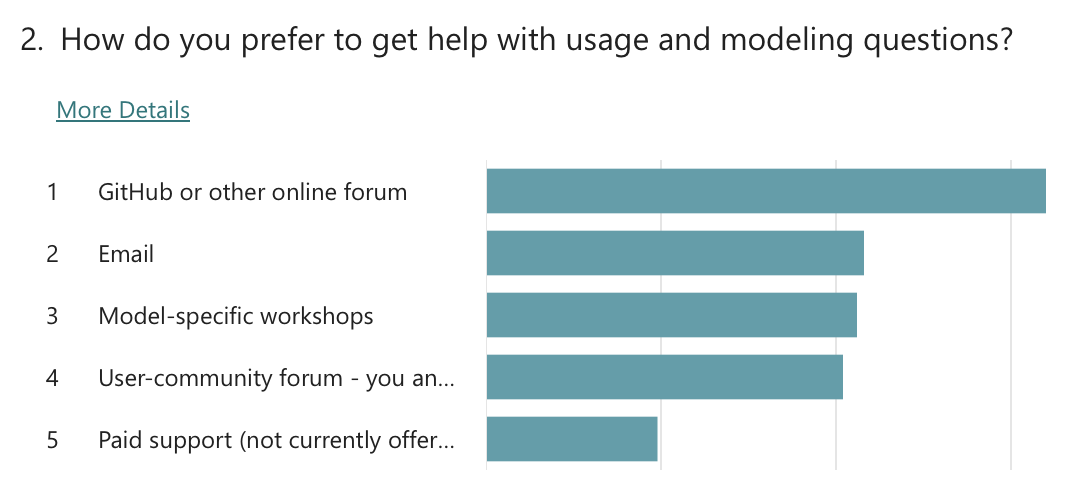
In each workshop, questions were asked about existing and future user support options. As for existing support, attendees noted that they mostly receive help from the model owners via the NREL Forums and GitHub-based forums, and that they also use the documentation and examples as a reference. On future user support, the questions asked attendees to rank support options in order of priority. The questions in each workshop were different, so a direct comparison is not made. However, respondents generally settled on the following ranking:
Community forums
Model-specific workshops and trainings
Improved examples
Improved documentation
Paid support
Upcoming Development Focus Areas#
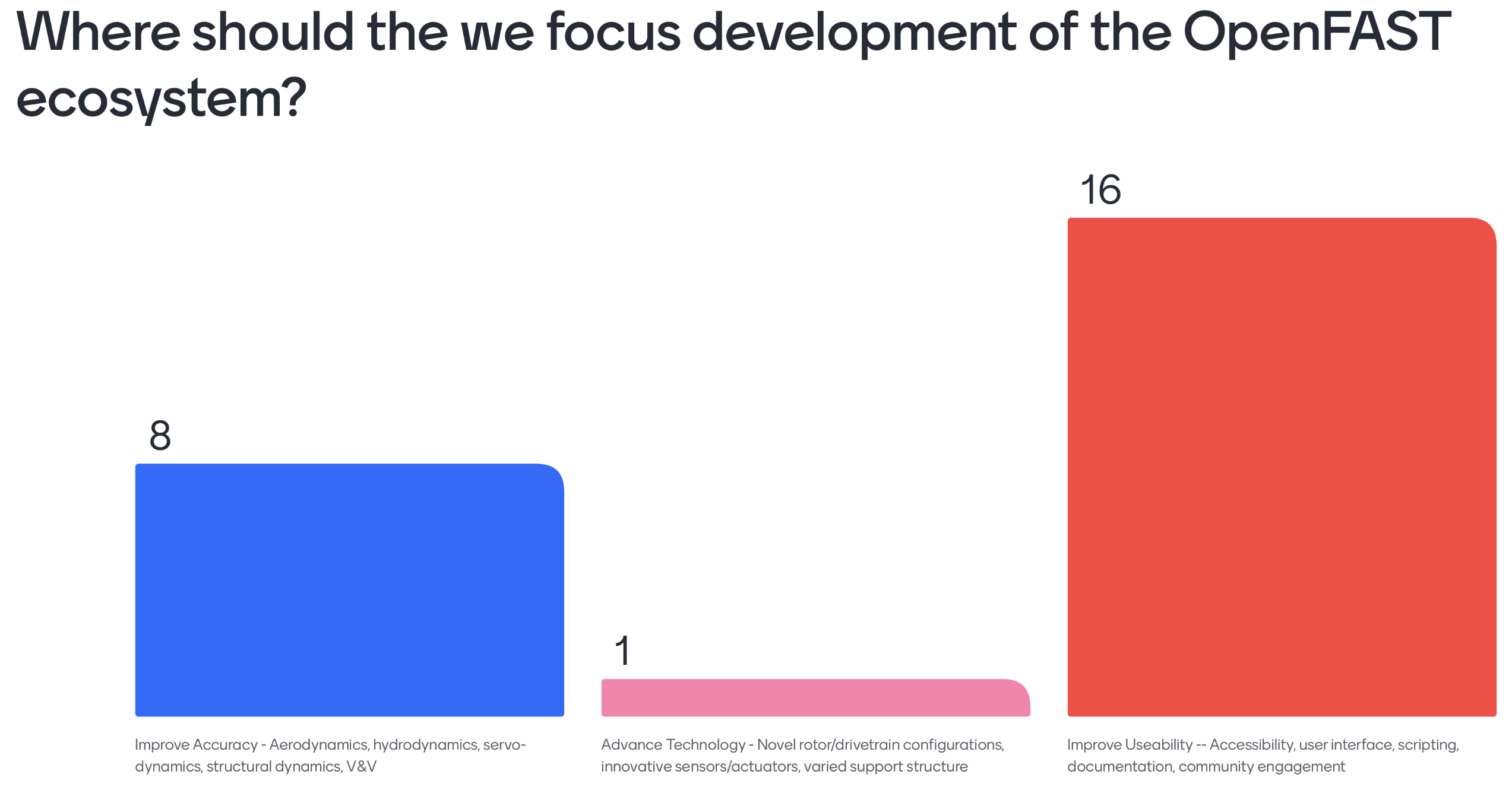
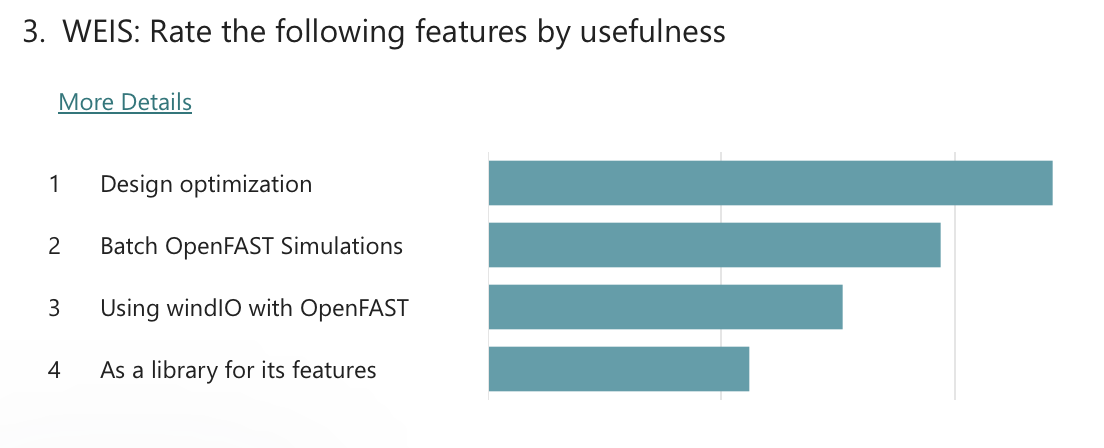
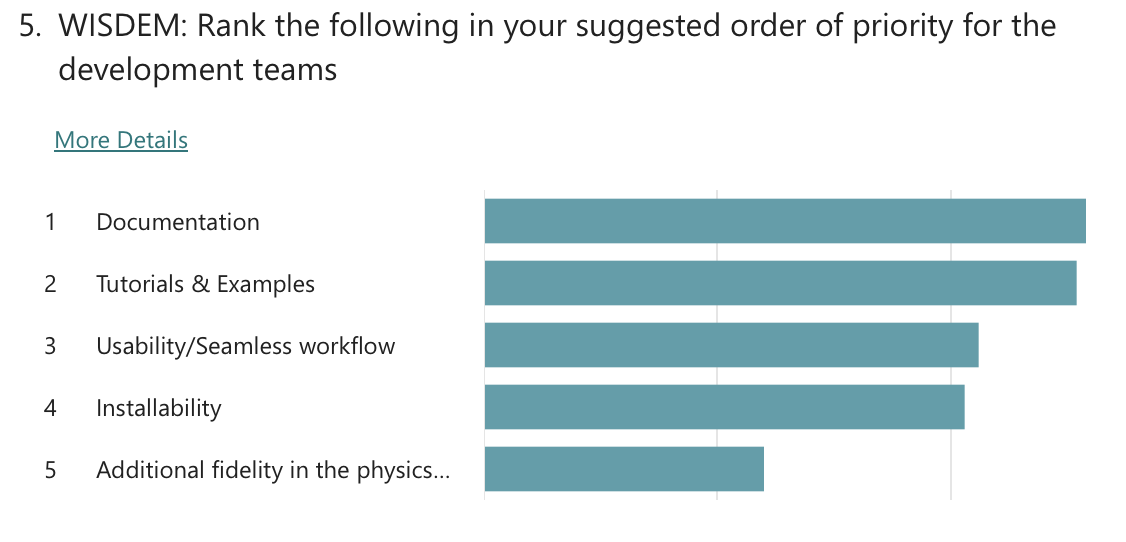
Polls were conducted to understand the community’s priorities around future development of the WETO Stack. The questions evolved throughout the series of workshops, but the results overwhelmingly indicate that the community supports focusing on usability and accessibility improvements. Specifically, “Documentation” and “Tutorials & Examples” were the clear favorite with “Installability” and “Usability / Seamless workflows” coming after.
As an indicative example, a poll in the OpenFAST workshop asked attendees to write in their top priorities and displayed the answers in a word cloud. Of the 31 responses, 26 were related to accessibility issues.

Workshop Feedback#
Attendees were asked to rate the workshops on a scale of 1 to 5 at the end of each workshop, and a follow up email was sent including an opportunity to provide anonymous feedback. The feedback was generally positive and each workshop received a rating of 4 or higher out of 5. The questions and responses are given below.
The anonymous feedback included more detailed suggestions. In general, there was an appreciation for the big picture overview of the WETO Software Stack. Respondents also noted that it was helpful to hear about the future roadmap from the model owners directly. The redundancy across workshops was called out as a negative, and many comments suggested to hold workshops for specific software.
Future Workshop Planning Material#
This workshop was planned and coordinated by Rafael Mudafort with help from Garrett Barter and Pietro Bortolotti. Reach out to them for questions on future workshops and to obtain access to the slides and other materials from these workshops.
Workshop recordings were posted to YouTube in the WETO Stack User Workshops 2024 playlist.
Registration#
The registration was handled through this Google Form, and the link was distributed via email and LinkedId. Google Forms has an option to put all of the data into a spreadsheet, which was helpful for tracking the registration count and to know which attendees registered for multiple workshops.
Meeting Platform#
The meeting was held on Microsoft Teams and the meeting link was distributed through a calendar invite. Note that attendees were added in the BCC field to preserve privacy.
Polling#
The polling was conducted through the Microsoft Teams Polls app and Mentimeter. The Teams Polls app was clunky - the UI was not straightforward, it simply didn’t work for some people, and the presenter cannot easily show the results on screen while the poll is being conducted. After some trial and error with Polls, we tried Mentimeter for the final workshop and it was much better. There are many more options for types of polls and the results are displayed in real time. It was very helpful to be able to show the results and talk through them as they came in. Generally, this helped the conversation to flow more naturally, and it was easy for the attendees to navigate. Note that there is a Mentimeter Teams app, but the interface is as clunky as the Polls app, and it is blocked for some Teams users depending on their organization’s settings.
I suggest to use Mentimeter for future workshops.
Presentation Format#
Since these were user-focused workshops, the presenters were asked to provide an overview of their software including the models and methods used, a demo of the capabilities and how it is used concretely, and an overview of the future roadmap. Being nearly two hours long, we tried to keep the static slide count to a minimum and reserve time for open discussion. Also, it was difficult but critical to keep the sections to their preset time. When sections went long, attention was easily lost. The presenters were encouraged to include prerecorded demonstrations of their software within the presentation, and this was generally well received. In the portions of mostly static content, engagement noticeably dropped. Note that the prerecording videos embedded in a PowerPoint slide were not always reliable and the audio was often choppy. We found that a video with no audio was smooth and the presenter could talk over the video live.
Planning Schedule#
Leading up to the workshops, it was helpful to have coordination meetings to give guidance, answer questions, and finally practice the presentation before the event. Here’s a general schedule:
Time to Workshop |
Activity |
|---|---|
1 month |
Initial planning meeting with presenters |
2 weeks |
Coordination meeting with presenters |
A few days |
Presentation dry run |
1 day |
Enter poll questions, email agenda and discussion questions |
Lessons Learned#
Don’t hold a workshop on a Monday or the day following a holiday as this makes last-minute preparations difficult
Send an agenda and discussion questions to attendees ahead of time so they can have an idea of how to contribute to the workshop
Open discussions are painfully difficult; some suggestions:
Coordinate with a friendly attendee ahead of time to start the conversation
Rely on Mentimeter polling to drive the conversation
Have direct, answerable questions that you prepare to ask the audience
Test the technology with computers that aren’t NREL or DOE property to be sure that all attendees can access the meeting and the polling software
Discussion Notes#
In these notes, comments from the presenters are noted with their name in italics, but comments from the attendees are not attributed.
Systems Engineering#
Portfolio discussion
Suggestion to provide guidance on using the various software together to accomplish a given task
Although documentation, examples, and other user support may exist, it can be difficult to find it
The individual software projects may have examples on how to accomplish tasks within their scope, but describing how they can be used together would be helpful
Pietro: There is an intention to develop unified workflows and especially that integrate with windIO; this is a work in progress
Pietro: Workflows are very user-dependent, so addressing this need is a challenge for the model owners to navigate
It would be helpful to have user groups that are split into categories based on the type of work they do
There are developers, OEMs, operators, academia - All these have different capabilities and want to use various NREL software, but they need to do different things
Organizing these meetings and developing training specific to these groups would be helpful
Model owners could suggest “If you’re a developer with a problem, solve it this way and these are the tools that we have.”
Garrett: We could possibly leverage forums (NREL Forum, GitHub) for these types of questions
There’s a broad array of tools within this software stack, and it would be useful to be able to integrate in-house tools to complete a particular workflow
How can we integrate in-house models with the high-level methods within the WETO Stack?
SE discussion
It’s not uncommon to come across an example that doesn’t run due to outdated files or dependency libraries
Given that we have limited time to evaluate these tools, ensuring that things work as-is would reduce the barrier to entry
“I got the same feeling when I saw what WindSE can do. It looks amazing, but I know if I go and try it out I’m going to get stuck, and it’s going to take me some time.”
Garrett: We share these frustrations when we onboard to other tools or hire new staff, but we are limited in where our funding can be used and it’s not typically available for addressing these types of issues. The feedback is useful and we’ll use it to inform future funding cycles.
Rafael: We’ve developed a set of software quality best practices that address part of this, and we can work to adopt this further
Sometimes it’s unclear what each example is meant to show and what users are meant to learn from it
Include real-life examples of applications of these software
Rafael: Maybe it’s worthwhile to develop a story that is told through the examples
Dan: Possibly create an example template prescribing how to show inputs, outputs, and methods
Jeff: We could start with a basic example and build on it to a more complex case; definitely going to apply this feedback to WindSE
Garrett: We’ve also considered separating the examples from the source code to enable installing the software itself through a package manager and then accessing the examples separately
It’s difficult to understand what each tool actually does and where it fits into the big picture
Also didn’t know that there were webinars, so linking information to other places would be helpful
Dan: I know installation can be a pain and within NREL we’re able to offer hands-on help, but this isn’t possible to do for everyone
Is there interest in a paid support option for installation or other usage questions?
Jeff: As developers, we’re blinded to the issues for new users because we created these systems and spend a lot of time with them
Rafael: You only have the unique experience of seeing something for the first time one, so it’s really helpful to hear your struggles and feedback on the onboarding process when you’re experiencing them
Feel free to engage directly with us on these problems
The reference systems that Pietro and co are creating could be a good way to show case this set of tools
Suggest to open source the reference turbine design process as a demo
Related, many of these tools interface with windIO - how do you see the ongoing engagement with windIO?
Rafael: From the holistic modeling perspective, we intend to start integrating windIO more directly within the WETO Stack over the next year
Garrett: On the reference systems, some of the scripts that were used to generate past reference turbines are available online but they could be made more accessible
Dan: We need to document in a simple way how we did the IEA 22 MW design, maybe show all the different optimizers in WEIS via the 22 MW turbine
The wind turbine library really should be made more readily available - maybe something that could be easily imported to a script - it’s a real treasure trove
The different fidelities and scales were mentioned, but I don’t see information on how you plan to integrate multifidelity models throughout the stack
Rafael: There is some ongoing work here, FLORIS is being integrated into WindSE
Pietro: WEIS was an elevation of the fidelity over WISDEM, so now we can use OpenFAST for a higher fidelity model of the turbine over WISDEM
Going back to windIO, having the common input would really enable this
Jeff: Let us know if you have a use-case where you want to connect multifidelity models because this is often where new development comes from
Ernesto: In the past, a challenge of going from low fidelity to high fidelity is that you need to add more information to the inputs, so having a common input structure facilitates structuring the data up front
Meeting chat
I think pushing windIO forward as a universal input file format will facilitate to work with various of the WETO tools. It took us a while to juggle between WISDEM, openFAST, SONATA and some external tools. OpenFAST is not yet on windIO, right? But still between wisdem and sonata the windIO format was not defined 100% the same, so some adjustments were necessary.
Garrett: Thank you for that comment, Daniel. That is certainly the long-term vision, and progress is being made, although not always as quickly to help all projects
Is there any possibility to integrate nrel’s turbine library with wisdem? Maybe using windio? NREL/turbine-models
Garrett: Thanks for pointing that out, Julian. That repo is mostly maintained by the techno-economic team. Perfectly on-point to the discussion here that this needs to be better integrated into this effort
Hi folks, as I mentioned to Pietro,Garrett and Dan in the past, for us, keeping the various components modular and stand-alone as much as possible is key, perhaps aligned with what Fabian said. E.g., towerSE is a great example of stand-alone, but the blade used to be really intrinsically connected to so many other parameters of the turbine. This makes it difficult to use for other side projects, e.g., to use in VAWTs, or with external inputs/loads etc.. So in a nutshell, the modularity and leaving things in stand-alone as much as possible is our ask
Julian: There are plans to modularize the windio turbine schema, which can help this vision of each package / data format being modular and stand-alone
Garrett: Thank you, Rick. Although you have mentioned it before, it is also helpful to hear the signal boost in this workshop
an electrolyzer module for wisdem sounds very intersting! I think this is a rising trend in wind energy research
Pietro: it’s actually already implemented, but it’s currently living on the hydrogen branch of WISDEM. we’ll work to merge it sooner than later
Can you estimate blade lifetime (in years)?
Pietro: yes, at the 2D cross sectional solver + 1D beam fidelity level. if you are wondering about the 3D FEM level, pyNuMAD is your tool
Garrett: WEIS can estimate DELs for blades and use that in a design loop. We have basic capability to convert DELs to traditional estimates of damage accumulation, but as Pietro said, it would be best to couple with pyNuMAD
It would be good to have a energy load based model , so that we can model what ever the load is , electrolyzes, data centers , steel or aluminum factories and get a optimal sizing of the wind vs solar vs battery storage based on the needs of the unit consuming the energy
Chris Bay: We are working on this capability in HOPP and GreenHEART. We have it developed for a couple different technologies, including batteries, electrolyzers, and steel plants, and are working to make it more general. Good to know this is of interest!
Is there now an automated set up to go from windio/wisdem to raft to do substructure optimization for floating platforms? It looks like it?
Garrett: Yes, the same WindIO/WISDEM input files can also drive the WEIS tool. WISDEM is always run and the user opts for which higher level of fidelity to run too (RAFT or OpenFAST)
About WISDEM: Sometimes it’s not self-explaining to work with the output file. If I’m searching for an output variable I’m basically searaching the csv file with a search tool. But if you don’t know the exact variable name or if there is no description added it can be tricky to find the correct variable. For some variables it’s also not always clear what the underlying grid is (e.g. power curve is a good example, you’ll finde powercurve.V for the underlying wind speed grid. But for some blade resolved variables it’s not always clear). That’s what I also realized when students work with wisdem. Some additional work on the documentation would help newcomers for sure
Garrett: We definitely acknowledge this usability issue. If you have suggestions on a better approach besides documentation, please mention it in the Q&A coming up
Maybe the output power curve could be in the windio plant-turbine schema
Garrett: That is a good idea!
What kind of computer was that optimization (from the WindSE demo) run on? A regular engineering laptop or an HPC?
Ethan: That optimization was run on a macbook, and the 13 hours was just wallclock time, but a windSE environment can also be set up on the HPC fairly easily. That would have allowed us to put a higher-fidelity solve into the optimization loop.
Which optimization solvers/algorithms can be used with WindSE?
Ethan: For the most part, we use the algorithms packaged with SciPy, specifically using the SLSQP and BFGS algorithms for most of the solutions. We’ve also supported a connection with SNOPT in the past, but that’s been harder to maintain due to running into license issues.
The reference systems developed by Pietro and company in the refwind task seem like an ideal opportunity to open-source the design process and showcase these tools in action. Almost all of these tools rely on WindIO. As the ontology develops, how do you anticipate dealing with new WindIO versions
to answer Daniel’s question (regarding whether paid support would be worthwhile) we will pay someone to onboard if we see value from clean energy developer stand point, open to engage on how that will look like, but broadly we need to convince our management of value here, which we think there is , but we need to get a outline for our particular use case
One thought on the new user experience - it might be useful to simply observe your intern/new researchers as they try to install and use the tools, rather than walking them through the installation and use process. It is probable that where they struggle is not unique to them, and could indicate an area of opportunity
And also bear in mind that not all users have the same level of familiarity/comfort with code-based tools and command line interfaces - if there are useful intro coding references, it would be nice to link those somewhere in the documentation ecosystem
Technoeconomic Analysis and Cost Models#
Portfolio discussion
How are assumptions in the cost models developed and communicated?
Rob: Expanding the software documentation and publishing these methods is a focus of the upcoming year of work, and it is already included in the future roadmap
Meeting chat
Interested to know if there are any tools in development to handle end of service or end of life of wind farms and decommissioning pathways. Especially TEA and cost models of these processes.
Garrett: Both ORBIT and LandBOSSE, which will be presented today, have line item costs for decommissioning, but those end-of-life processes are not modeled to the same resolution as assembly and installation at the front-end
Thanks. Do you have any interface with TECHTEST that DOE EERE published?
Garrett (answered in the meeting): This specific set of software do not integrate with TechTest, but this is a good suggestion ad we’ll note this for future development
Another question from a prospective / new user perspective… many industry assessment packages (i.w., Windographer, Furow, etc.) have GUIs that lessen some of the challenge with onboarding. Is there consideration for making GUIs for some of NREL’s packages (such as ORBIT)?
Garrett: Hi Keith- This topic does come up a bit. Our DOE funded work tends to emphasize the research & study functionality instead of the GUIs. GUIs also tend to require a higher level of maintenance to ensure that everything always works smoothly, so they haven’t been as high on the priority list. Feedback such as yours is exactly what this workshop is about and will help us adjust our roadmaps accordingly. I’ll add that some of NREL’s wind TEA tools couple into NREL’s more widely known System Advisor Model (SAM), which is GUI-based. Also, as Rob just mentioned, LandBOSSE has an Excel tie-in
Author: … I should have mentioned SAM; I have used that and if an ORBIT interface could be added, that would be great
Comment related to LandBOSSE – It would be beneficial if the documentation about used inputs and outputs is a bit more detailed. Especially for new users, I found it hard to navigate throughout many excel sheets, without knowing the naming convention, units, references etc. Maybe to be considered for the future LandBOSSE report…
Rob: Another spoiler is that LandBOSSE is slated for some general updates both for some more modern Python, but especially to get a documentation site (currently relies on the user building it locally)
Question for Nicholas, based on what information you create and update your models?
Nicholas: Hi Ernesto. Thanks for the great question. Models tend to receive updates project-to-project. We reference a variety of published manuscripts, leverage other NREL teams for engineering model trends, communicate and verify approaches with industry partners, and also distill information that gov or developers release.
Question to Rob: Do you have plans to introduce models accounting for the effect on the probability of failure of components and sub-components considering climate change events?
Question to CORAL, does CORAL select the type vessels and cranes based on wind turbine manufacture information (e.g. blade length and weight, type of substructure)?
Sophie: CORAL does select vessels types based on the substructure type, but turbine size influences the number of kits that can be fit on each vessel (effecting the number of trips to site for the vessel)
WOMBAT: Hi, Do you plan to add SOV vessel and helicopter classes?
Rob - how do you model/forecast weather conditions? Where are these wind/waves timeseries come from, and how confident are you that they accureately represent long/short term conditions?
Rob: Currently we use reanalysis data for the weather models, though we’ve kicked the can down the road for many years on creating our own weather model
Author: Reanalysis data refer to a record of past weather. Are you using reanalysis data to initialize a forecast? Or you only consider past events?
Interested to know if there are “standard” real wind farm models that can be used compare with. Like software testing or earthquake models. Benchmark models.
It would be great to see the possibility in WOMBAT to use SOVs and helicopters, together with the possibility of defining a “priority” for vessels based on the type of failure
Rob: Could you provide more on the priority modeling for vessels? The others are definitely on our radar to address!
I.e. CTVs and helicopter (that can be defined as a CTV with different operational limits) are defined in your project, prioritize which “vessel” will go offshore in case metocean allows both to go offshore. In this case you would like helicopter to always stay if CTV can go. Hope I made myself clear. Thank you for the session!
Rob: This makes a lot of sense! Currently it cycles through the available servicing equipment by needed category, but this would definitely align better with informing decision making/what-if modeling
Wind Farm Controls and Analysis#
Portfolio discussion
Confusion has been around what model do I choose for my particular needs?
So if I want to do some sort of mid fidelity modeling, how do I choose one tool over another?
Ideally, there would be a guide that serves as an entry point to the WETO Stack
Rafael: For that specific question, FAST.Farm is a good start, but generally I think a mapping of the software at one level higher than the mindmap that we currently have would be helpful
WFC&A discussion
From the polls, “community forums” were voted as the user-support option that is more desired
Having a starting point and classification of the tools would be helpful to new and experienced users
Different models can do many things, but now I have too many options so how do I choose one and use them effectively
Garrett: Would something like a decision tree be helpful?
Are you looking for steady state or unsteady?
Are you working on a laptop or HPC?
Rafael: Based on an earlier question on coupling mid and low fidelity models, is Hercules expected to support multiple models across multiple fidelities?
Misha: Hercules is specifically coupled to AMR-Wind, the “H” is for “hybrids” but you could only simulate wind energy
The aim is that you could switch the higher fidelity model and run something like FAST.Farm and even run WHOC over FAST.Farm
Yes, ultimately the aim is to integrate a more realistic engineering model, but the timeline is unclear
Rafael: For those who have contributed back to these repositories, what has made that easy? For those who haven’t, what holds you back?
Hosting on GitHub really helps; ultimately, retaining competitive advantage is a major consideration and does prevent contributing back to the open source repository
Having a plug-in architecture to many of these tools would be helpful for people to be able to swap components, as needed, and contribute back to specific sections without having to decouple a lot of the code
Garrett: How much is there interest in multi-fidelity workflows? Would fostering this through a common input file like windIO be helpful?
When I look at something like WindSE or FAST.Farm, I’m starting from zero with that, so a common input file would be helpful to ease the burden of getting started
Rafael: I have a strong desire to make contributors to FLORIS feel like this is their model as well as ours, so any suggestions on how to do that would be helpful
It’s helpful to be able to contribute back to the open source repository because it allows us to keep our work up to date with the latest developments
One thing that would be good is to explicitly acknowledge the people and organizations that contribute back somewhere in the repository
This is something that we could bring back to our management in that it’s good PR
Regarding privacy concerns, I think many companies would be happy to share that they’re using and contributing to FLORIS, but they just aren’t being asked
Users and industry partners can connect with NREL researchers on an individual basis, but is there an opportunity for a forum model owners can share they future plans more generally?
An online meeting or other live event where stakeholders (users, contributors) who have contributed to FLORIS are invited
Rafael: Whats a good way to advertise these types of events?
Meeting chat
This workshop’s chat was mostly inactive.
OpenFAST Ecosystem#
OpenFAST discussion
How to communicate information broadly about updates and events relate to WETO Software?
An email newsletter is good, but also putting information on the internet is helpful so that others who aren’t subscribed to the email can also find it
If you have a new model or want to make changes to an existing model, whats the recommended sequence of steps to do this (specific to ROSCO)?
Dan: Workflows can be specific to users, but generally I start with an example similar to what I want to do and then make a few changes
Demos are helpful, but including information on how to make the results happen is an important level of detail
How do you approach backwards compatibility?
Andy: We’re looking at ways to continue supporting old versions starting with v3.5.
In terms of supporting input file converters, this isn’t something we have the resources to support
Dan: ROSCO has moved to a format where most of the inputs are optional, so backward compatibility is easily supported
Keeping in sync with WEIS and other adjacent software is more challenging, but we’re testing processes for navigating this
Lots of discussion around processes for contribution back to the OpenFAST ecosystem and especially the openfast_toolbox project
Meeting chat
Hi Derek, great tool ACDC! What openFast modules are supported? ElastoDyn or also BeamDyn? ServoDyn fixed bottom or also floating? Can one set manually the degrees of freedom in the elastoDyn file?
Derek: It’s been pretty thoroughly tested with ElastoDyn, BeamDyn, and AeroDyn. If you can normally do linearization in OpenFAST it should be supported by ACDC. The visualization currently only supports lines so SubDyn doesn’t visualize very well, but frequencies and damping are correct. It has worked on floating as well, though it doesn’t visualize the platform
How does the External DLL option work?
Derek: Yes, you can set which DOFs are active in ElastoDyn through the interface as well. ServoDyn is supported as in typical OpenFAST linearization. So, it adjusts the blade pitch or the torque (based on the region) to achieve the target wind speed and rotor RPM.
Dan: It works almost exactly like ServoDyn calls ROSCO. ROSCO can load and call another DLL, then it’s up to the user to decide how to use the information from the external DLL. In this example, a ROSCO DLL calls another ROSCO DLL: NREL/ROSCO. It was developed because users sometimes have black box OEM DLLs and want to add features, like floating support, to those controllers.
Anurag: Thoughts in the audience on how you would best want to join in/integrate into a broader OpenFAST development community to speed up progress on the roadmap ? What framework/arrangement/support would make a difference ?
Do you mean for user-contributed developments? For feedback?
Anurag: User-contributed developments (OR) improvements to elements to the OpenFAST “toolkit” broadly
We have scripts internally to do things like run a power curve or other types of sweep using yaml inputs to swap out OpenFAST inputs. Are tools like that widely available?
If they are available, my perspective is that they are not easy to find (either that or not available)
Maybe we should share those!
Garrett: On the python toolboxes, the NREL team would like to see a future where all of the python-based utilities in the openfast_toolbox, WEIS, pCrunch, and others all get combined and cleaned up into the primary openfast_toolbox that was just described. It will take some time and the right project support to make that happen though.
maybe there is a possibility of a “cheat-sheet” kind of an approach (?)
(Related to the initial question) Could an open Discussion thread on GitHub where users can suggest improvement ideas work? Then, if others have existing tools addressing those needs, they could share it (maybe to a new folder within the repo?)
Maybe more of a curated FAQs?
Andy: Adding bit more regarding long term support of OpenFAST releases. Historically we have dropped support for old versions as soon as a new version is released. Going forward we intend to port bugfixes to older versions starting with our 3.5.x version. So after 4.0 or 5.0 are released, we intend to address minor bugs in the 3.5.x series with new minor releases for a few years. However, we won’t be able to add new features to older versions – so a new feature in 4.0 or 5.0 would not be included in a future 3.5.x bug fix release.
I don’t really know how this works, but this sounds like it could only help with compatibility with other softwares. For example, we’ll be less likely to have to update AMR when OpenFAST updates, right?
Andy: Correct. The thought here is that we can continue supporting AMR-Wind with a set version of OpenFAST rather than forcing AMR-Wind to update. Previously if a bug was found, AMR-Wind would be forced to update to the latest version of OpenFAST to get that fix. Going forward all versions of OpenFAST where only the last digit of the version changes has no input file or interface changes. So a set of OpenFAST files from 3.5.0 will work seamlessly with 3.5.4. Our hope with this approach is that it is easier for end users to integrate a given version of OpenFAST and know that they will get future bug fixes that don’t require completely revising their integrations. However if the AMR-Wind wants a new feature, then they will need to update to a later version of OpenFAST. I am expecting that AMR-Wind will probably use the OpenFAST 4.x series for a long time.
Raw poll data#
Systems Engineering#
Topic specific poll
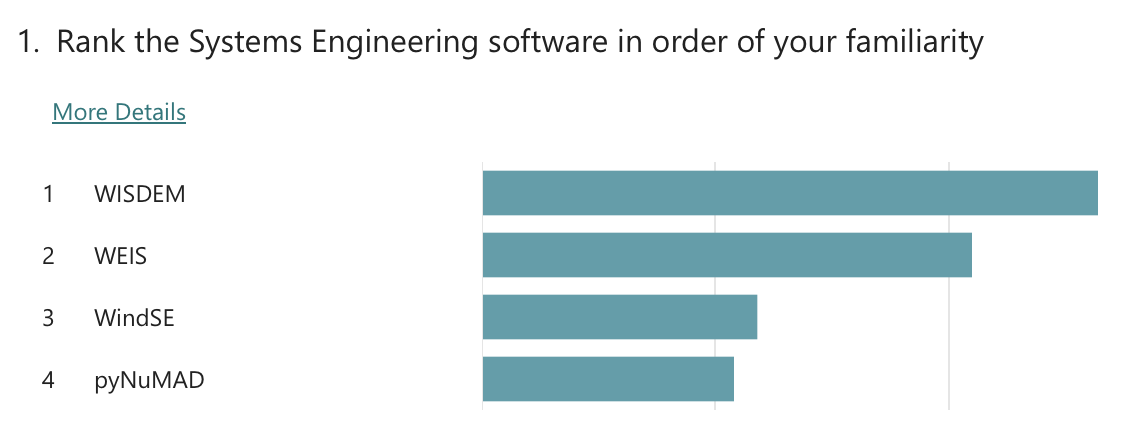
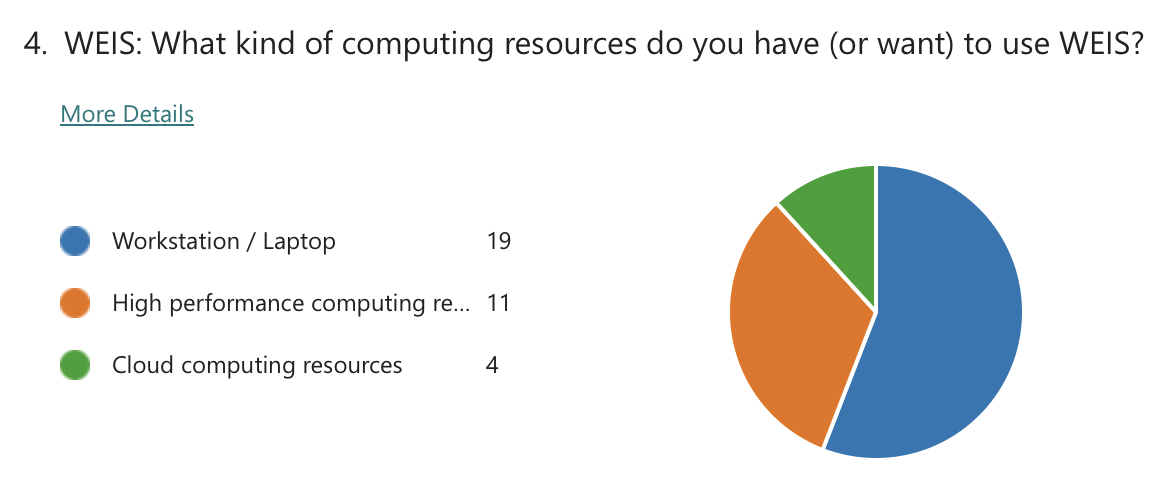
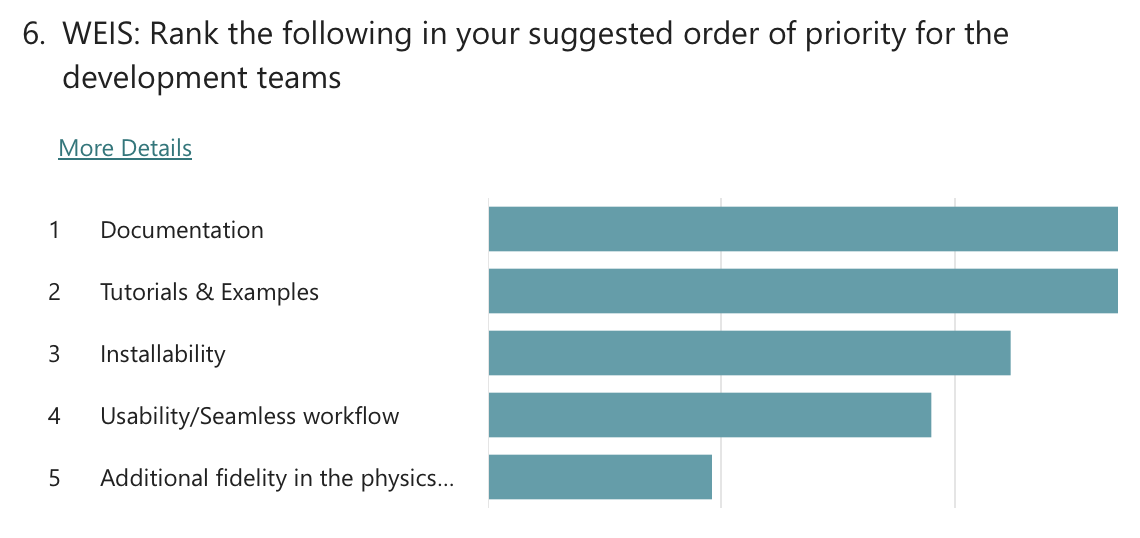
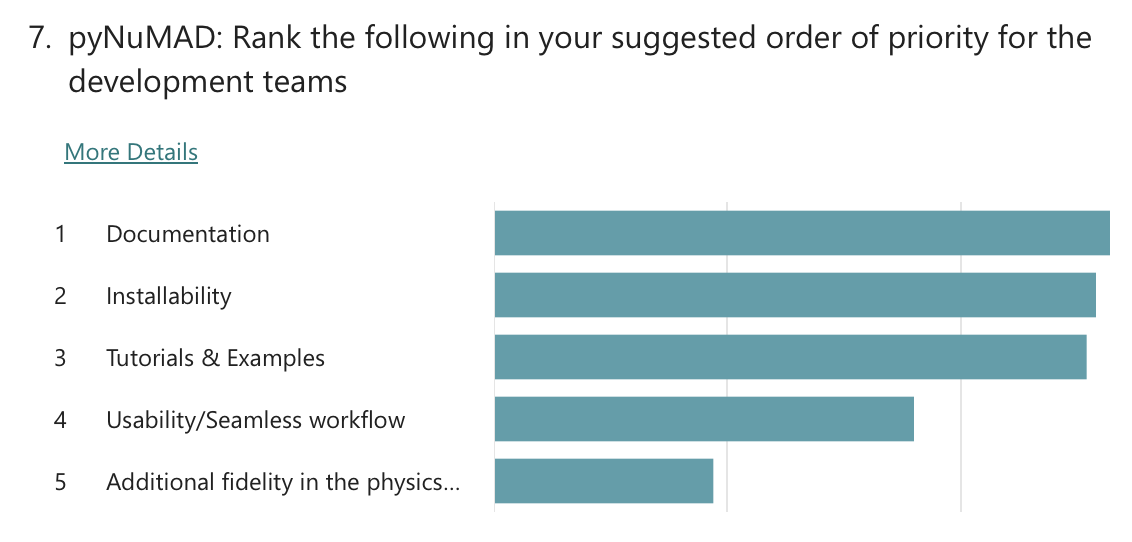
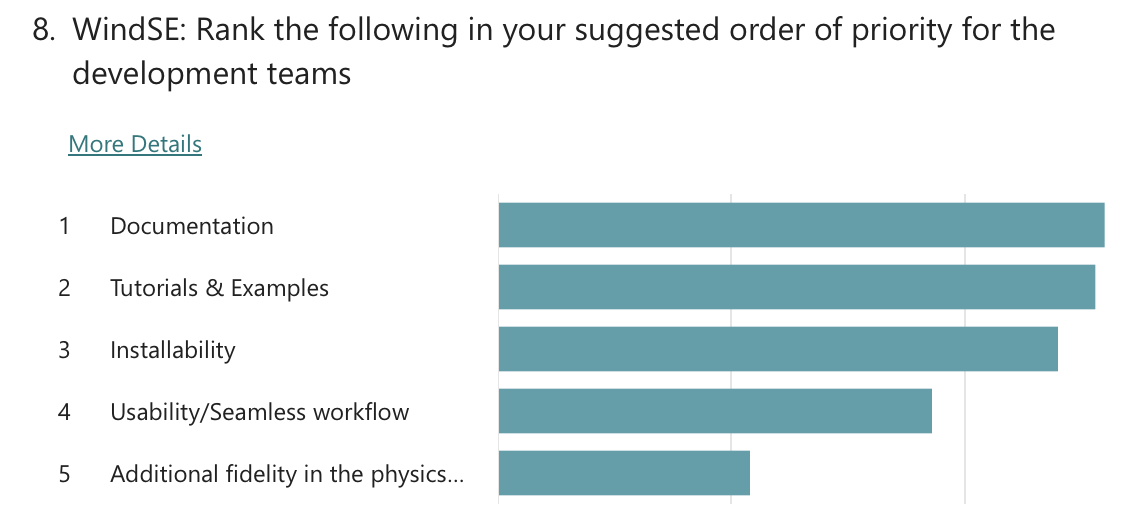
Exit poll



Technoeconomic Analysis and Cost Models#
Overview poll
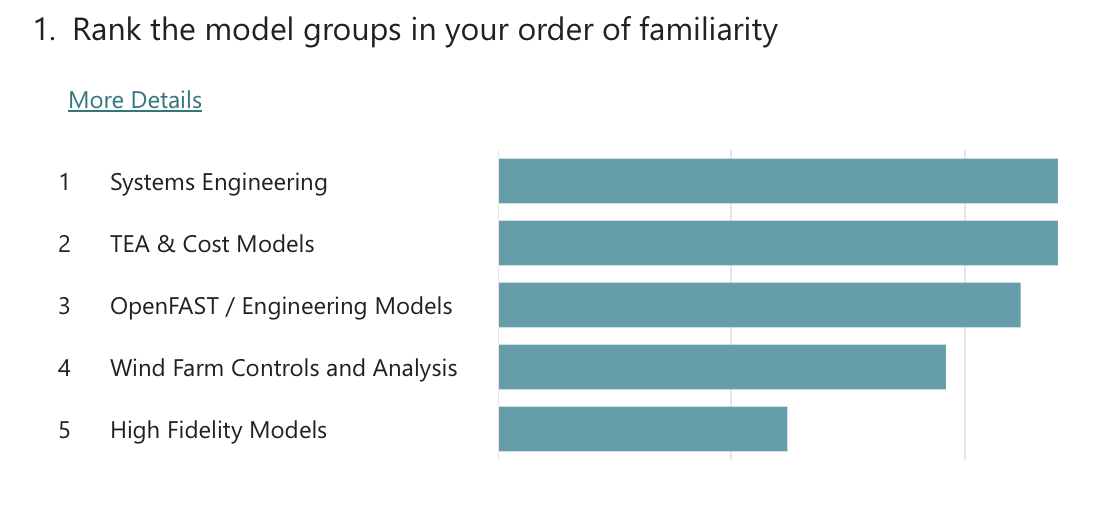
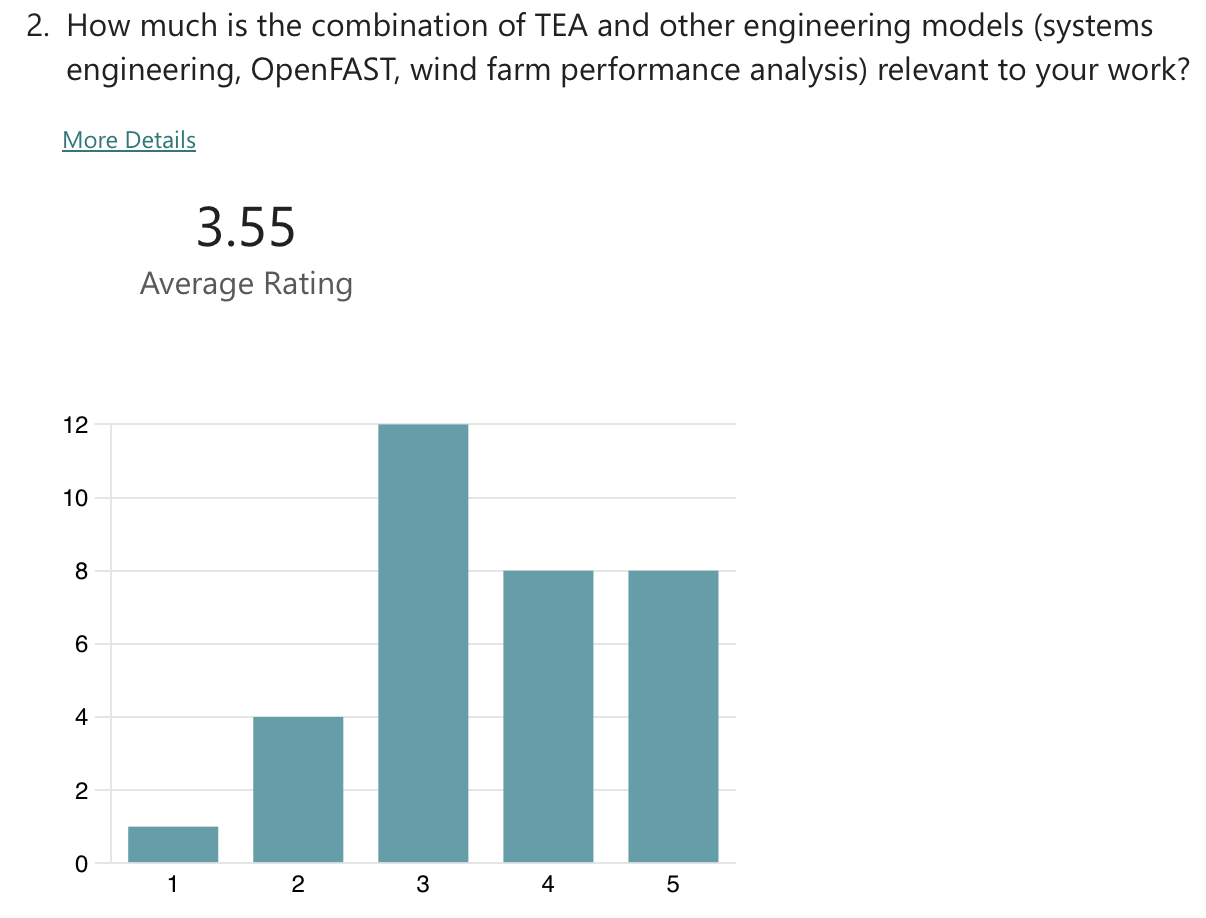
Topic specific poll
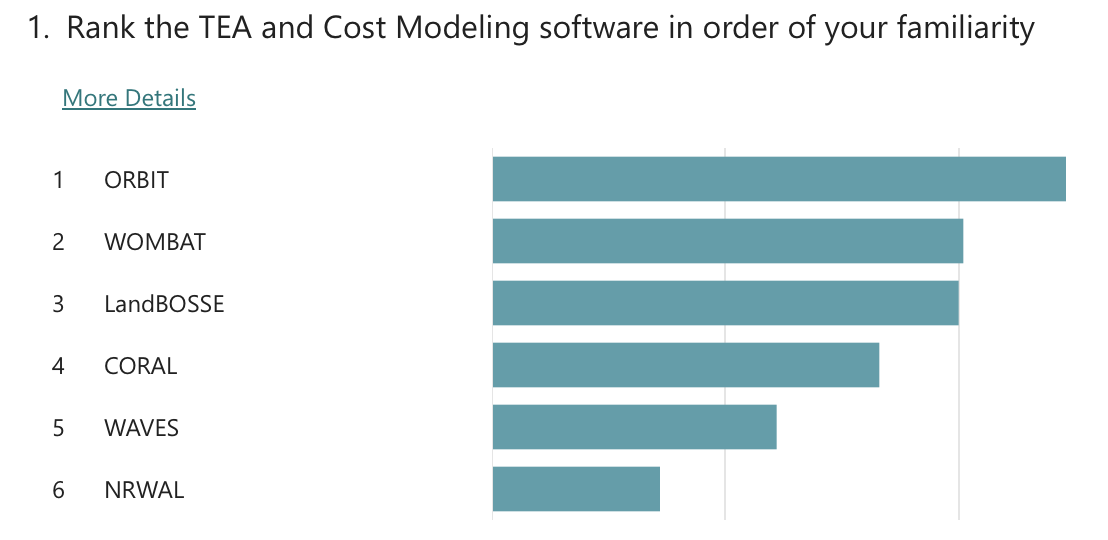
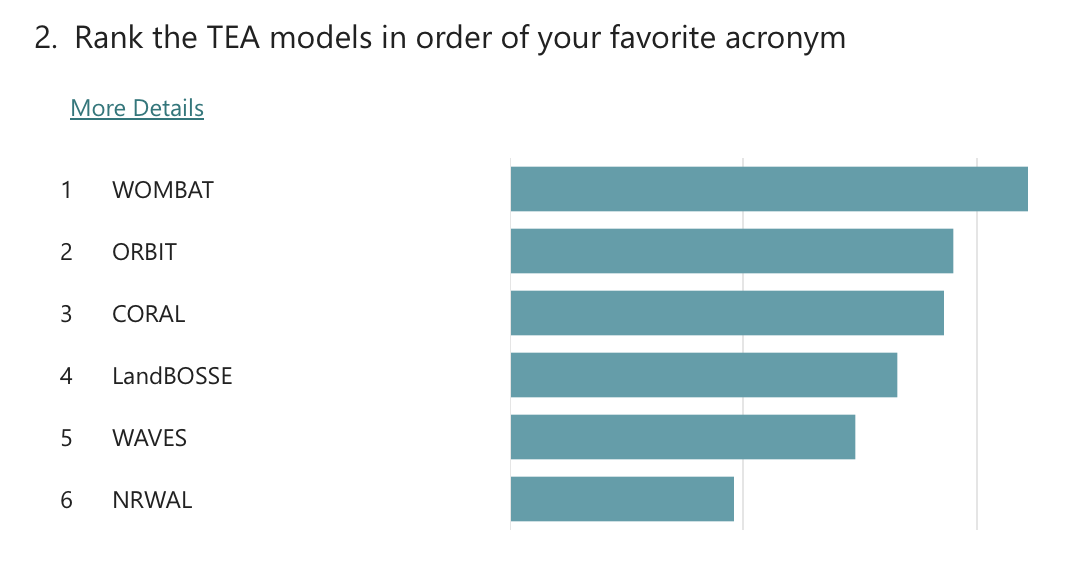

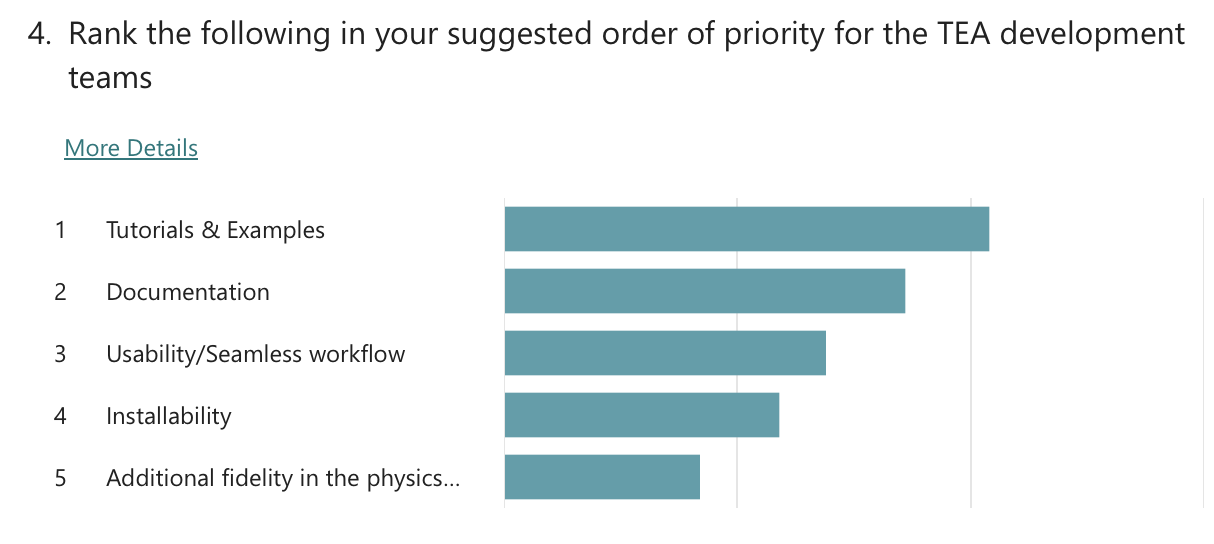
Exit poll


Wind Farm Controls and Analysis#
Overview poll
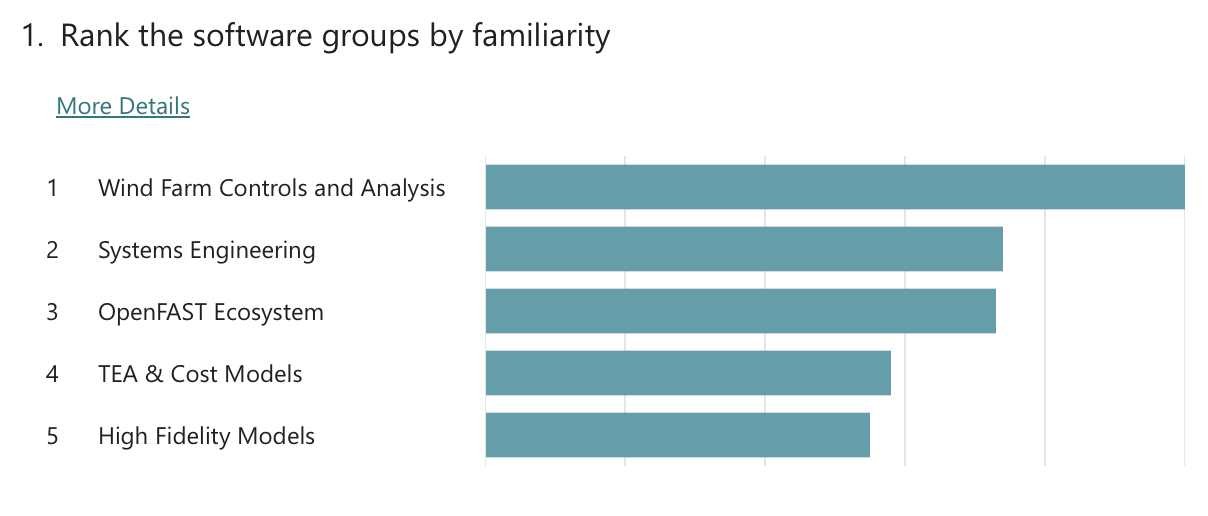
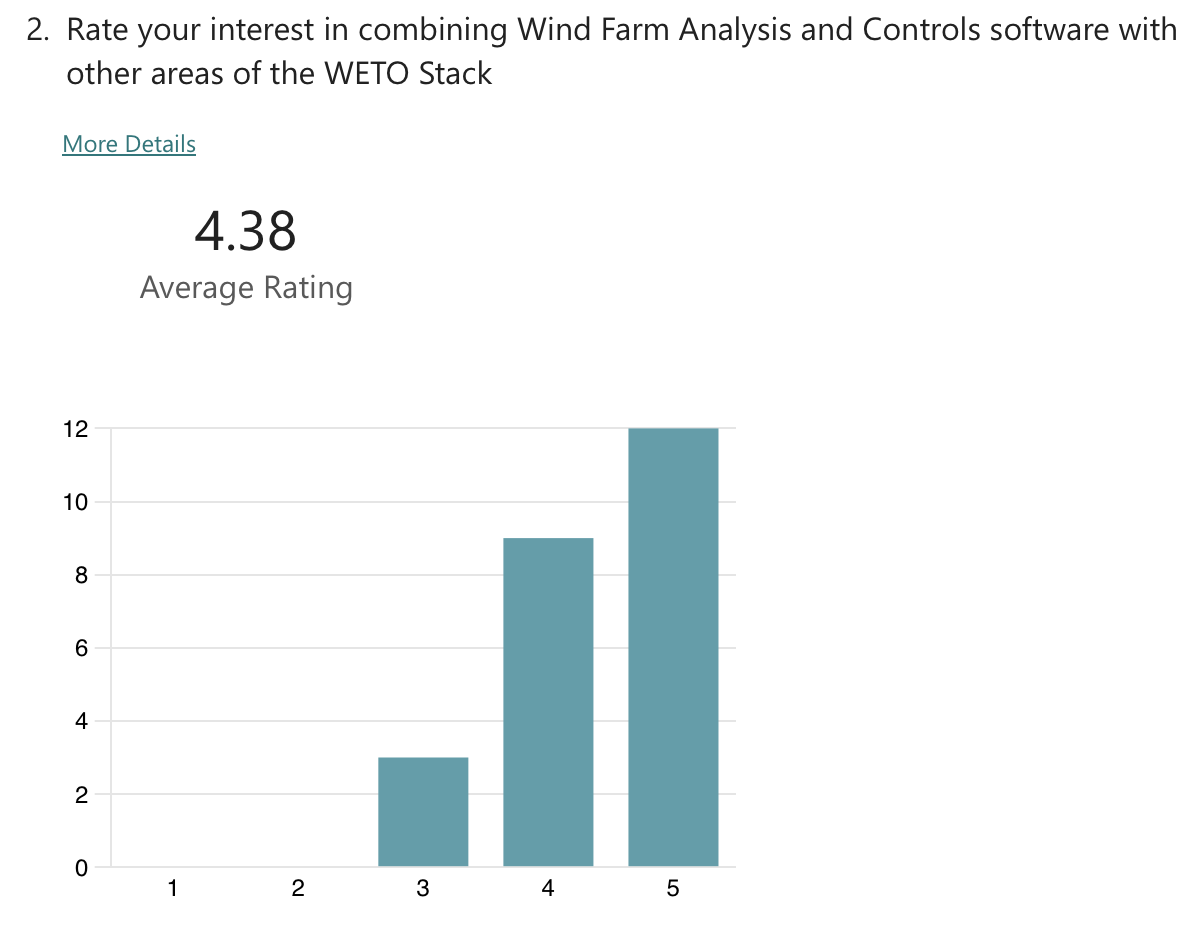
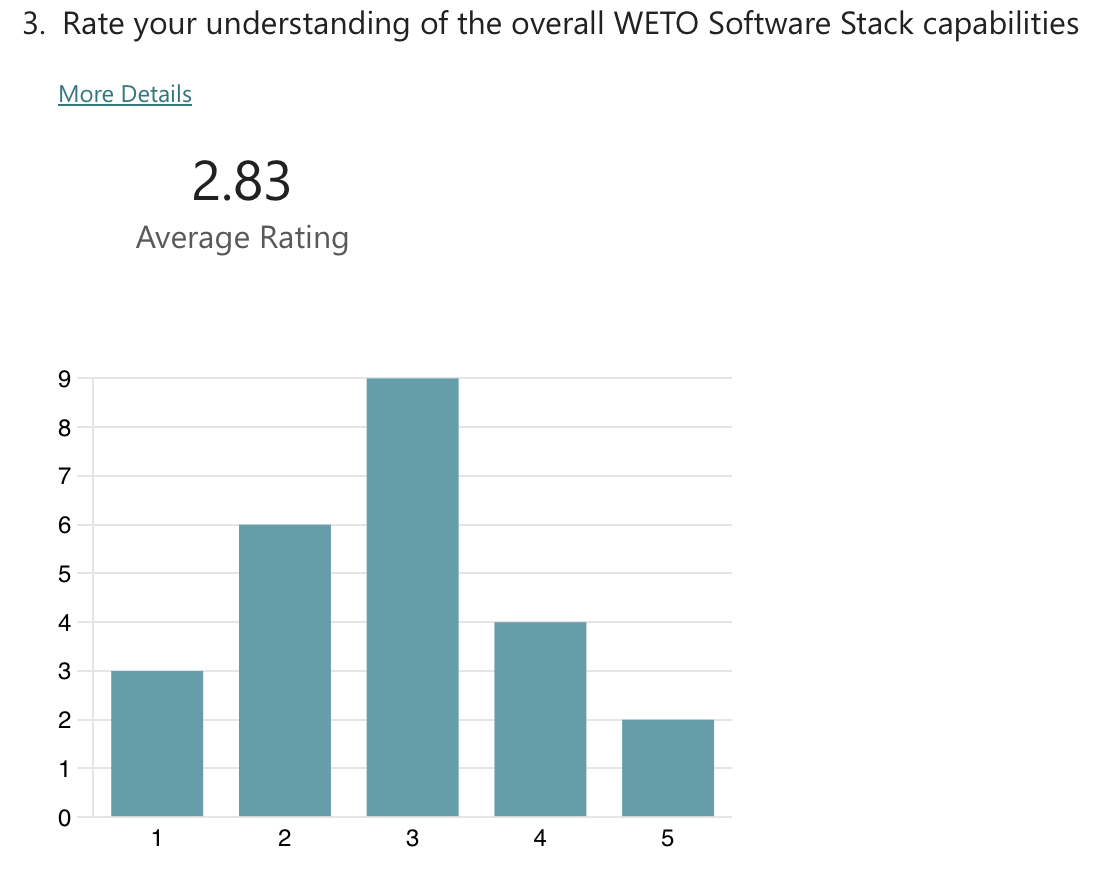
Topic specific poll
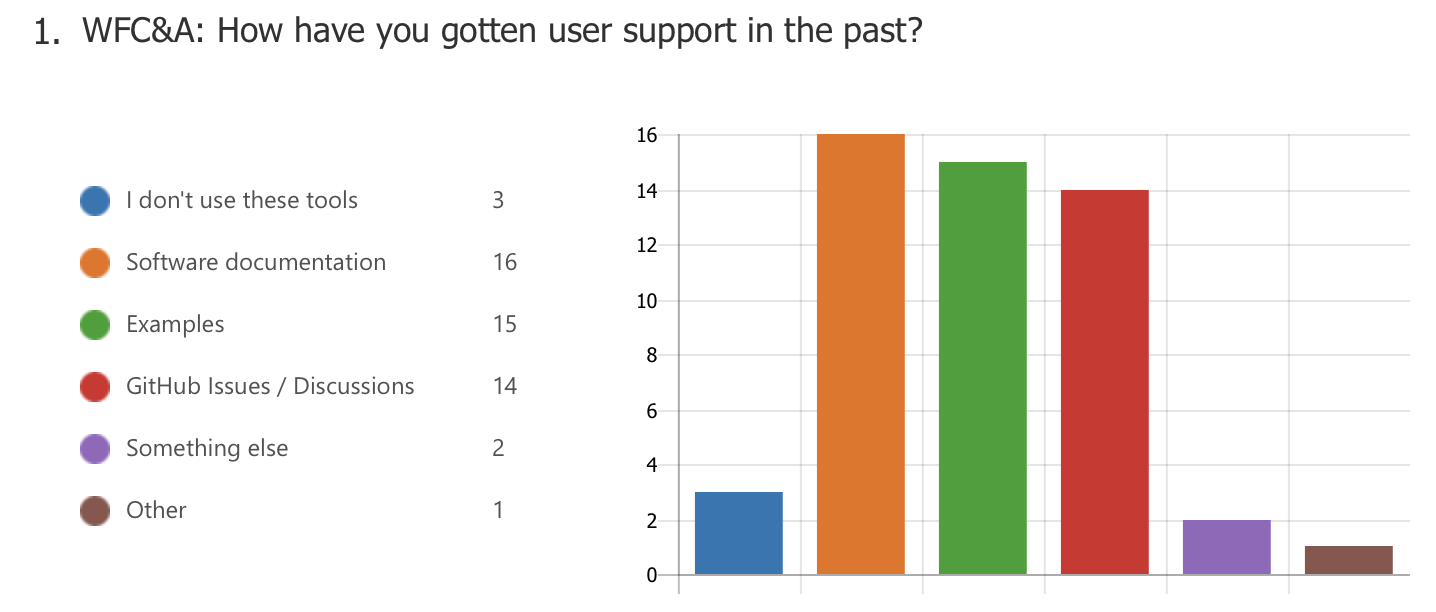
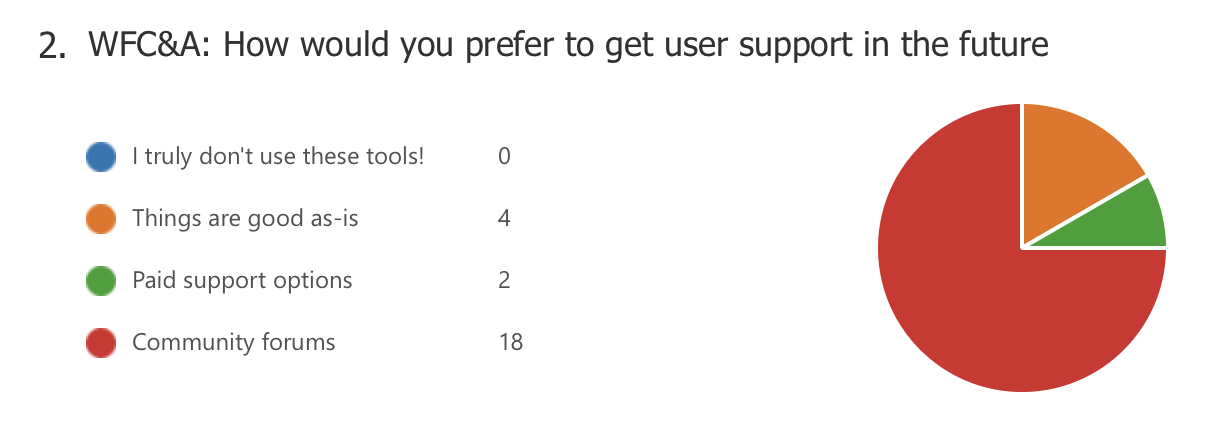
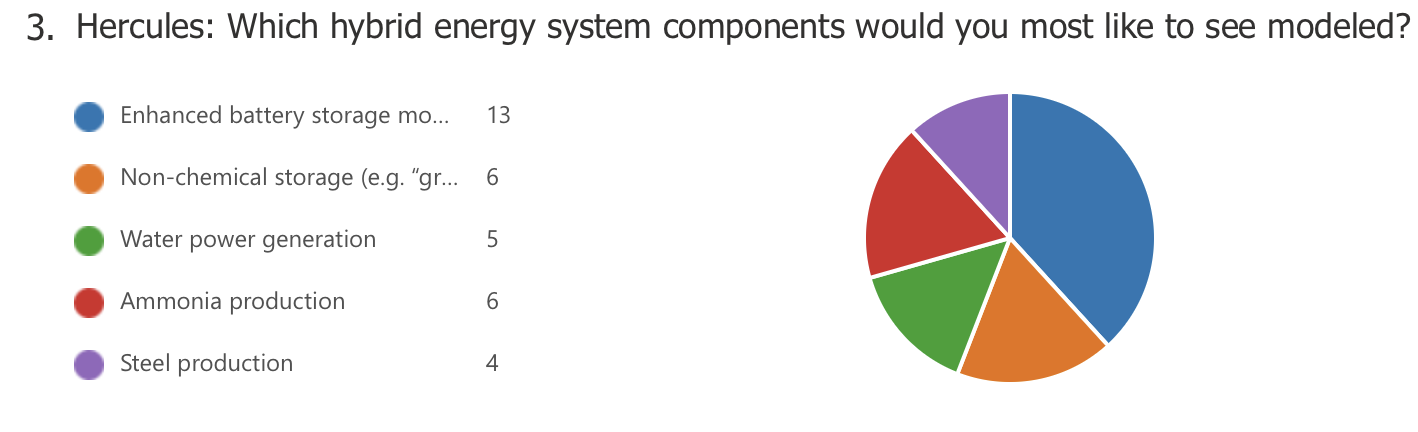
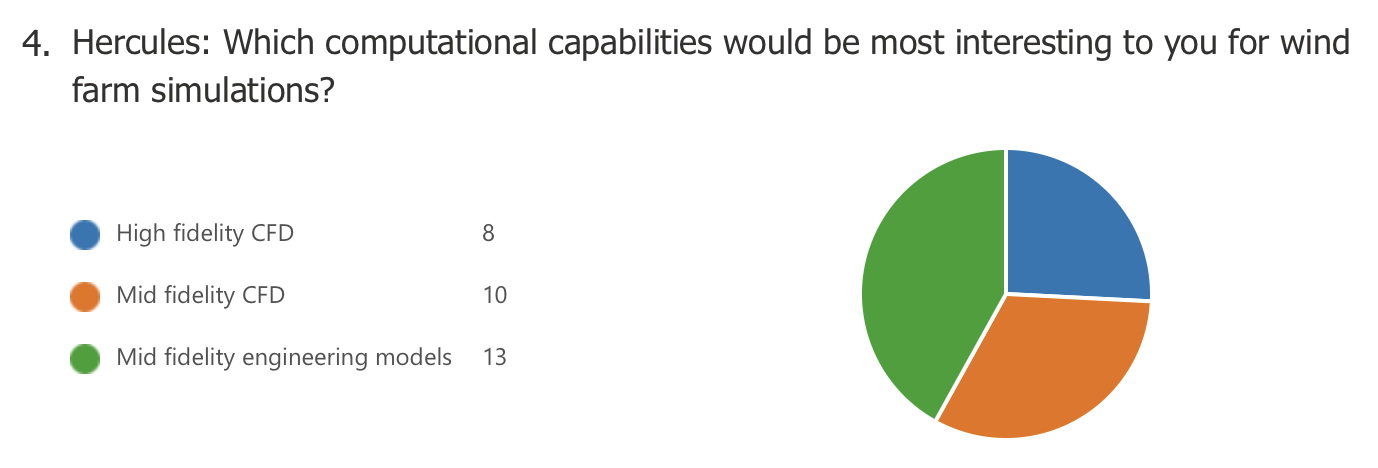


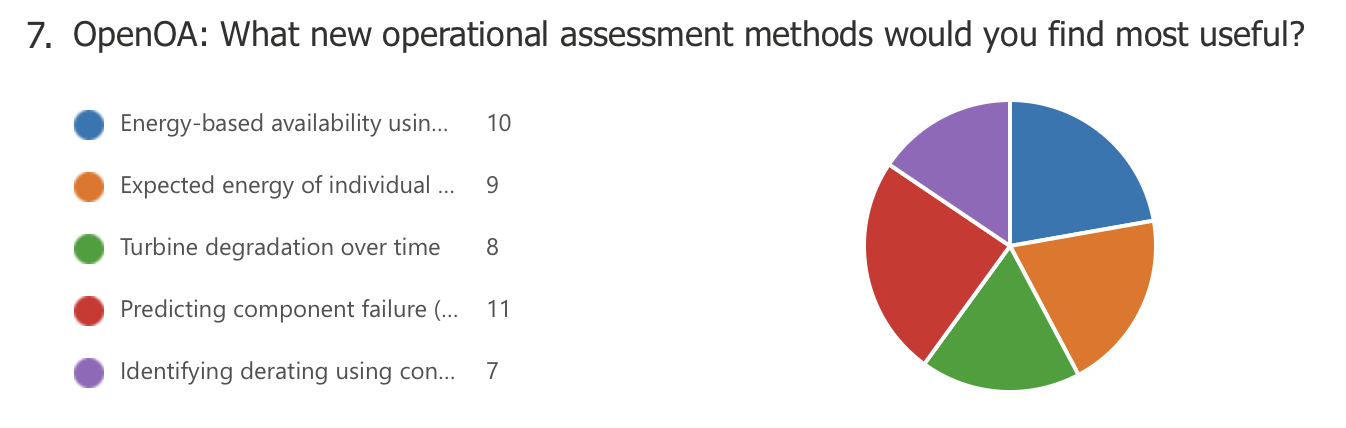
Exit poll


OpenFAST Ecosystem#
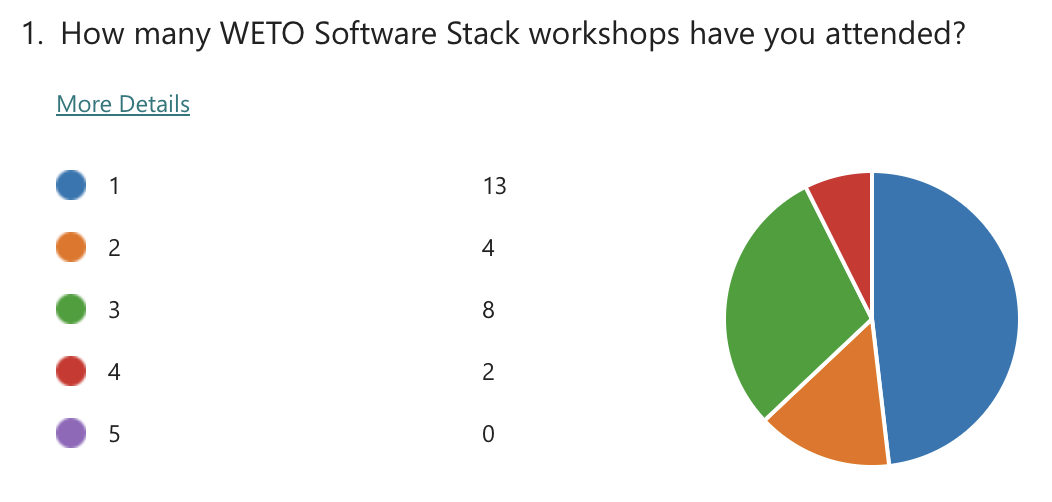
Topic specific poll